数据库抽象层(DAL)
DAL 简介
py4web 依赖于数据库抽象层(DAL),这是一种将 Python 对象映射到数据库对象(如查询、表和记录)的 API。DAL 使用数据库后端特定的方言实时动态生成 SQL,这样您就不必编写 SQL 代码或学习不同的 SQL 方言(通常使用术语 SQL ),并且应用程序可以在不同类型的数据库之间移植。选用的 DAL 是一个名为 pyDAL 的纯 Python 库。它是在 web2py 项目中构思的,但它是一个标准的 python 模块:你可以在任何 python 环境中使用它。
备注
pyDAL 与大多数其他 DAL 的不同之处在于语法:它将记录映射到 python 字典,这更简单,更接近 SQL。其他著名的框架严格依赖于 对象关系映射 ( ORM ),如 Django ORM 或 SQL Alchemy ORM,它们将表映射到 Python 类,将行映射到对象。
pyDAL 的部分特点:
事务
聚合
内联、外联
嵌套查询
备注
py4web 和 web2py 之间一个重要的区别是,只有少数几个字段属性可以在 actions 中安全地修改。更多信息请参见 线程安全和字段属性 ,以及从 从 web2py 迁移到 py4web 的一般差异列表。
支持的数据库
下面的表格显示了支持的数据库的部分列表。请查看 py4web/pyDAL 网站和邮件列表,以获取更新的适配器信息。
备注
在任何现代的 Python 发行版中,SQLite 实际上成为 Python 的内置库。SQLite 驱动程序 (sqlite3) 也包含在内:您无需安装它。因此,它是用于测试和开发的最常用的数据库。
Windows 和 Mac 的二进制版本开箱即用,仅支持 SQLite 和 PostgreSQL。在后端,要使用其他数据库,请运行完整的 py4web 发行版,并安装后端所需的相应驱动程序。一旦正确的驱动程序安装完成,启动 py4web,它将自动检测到驱动程序。
这里是一份 py4web 能够使用的驱动列表:
数据库 |
驱动程序 |
|---|---|
SQLite |
sqlite3 or pysqlite2 or zxJDBC (on Jython) |
PostgreSQL |
psycopg2 or zxJDBC (on Jython) |
MySQL |
pymysql or MySQLdb |
Oracle |
cx_Oracle |
MSSQL |
pyodbc or pypyodbc |
FireBird |
kinterbasdb or fdb or pyodbc |
DB2 |
pyodbc |
Informix |
informixdb |
Ingres |
ingresdbi |
Cubrid |
cubriddb |
Sybase |
Sybase |
Teradata |
pyodbc |
SAPDB |
sapdb |
MongoDB |
pymongo |
IMAP |
imaplib |
对 MongoDB 的支持是实验性的。Google NoSQL 被视为一个特例。本章末尾的 陷阱 ( Gotchas )部分提供了有关特定数据库的更多信息。
DAL: 快速预览
py4web 定义了构成 DAL 的以下类:
- DAL
表示数据库连接。例如:
db = DAL('sqlite://storage.sqlite')
- Table
表示一个数据库 表 。你不能直接实例化表,
DAL.define_table会实现:db.define_table('mytable', Field('myfield'))
表 的非常重要的方法是:
insert、truncate、drop、 和import_from_csv_file。- Field
表示一个数据库 字段 。它可以被实例化,也可以作为
DAL.define_table的参数。- Rows
Rows 是数据库查询返回的一个对象。可以认为它是由多个
Row构成的一个列表:rows = db(db.mytable.myfield != None).select()
- Row
包含字段值
for row in rows: print(row.myfield)
- Query
Query 是一个表示 SQL “where” 子句的对象
myquery = (db.mytable.myfield != None) | (db.mytable.myfield > 'A')
- Set
Set 是一组记录的集合的对象。它最重要的方法是
count、select、update和delete。例如:myset = db(myquery) rows = myset.select() myset.update(myfield='somevalue') myset.delete()
- 表达式
表达式(expression) 是用于类似 orderby 或 groupby 使用的东西,它们使用的 Field 来自 表达式 。这里有一个例子。
myorder = db.mytable.myfield.upper() | db.mytable.id db().select(db.table.ALL, orderby=myorder)
单独使用 DAL
pyDAL 是一个独立的 python 包。因此,它可以在没有 web2py/py4web 环境的情况下使用;你只需要使用 pip 安装它,然后在需要的地方导入 pydal 模块:
>>> from pydal import DAL, Field
备注
即使您可以直接从 pydal 导入模块,也不建议在 py4web 的应用程序中导入。记住 py4web.DAL 是一个 夹具 ,而 pydal.DAL 不是。在本文中,上面的导入命令因该是:
>>> from py4web import DAL, Field
使用 py4web shell 进行实验
你还可以借助 py4web shell 来试验 pyDAL API, shell 命令行选项 也可以使用。
警告
请注意,数据库更改可能是持久的。因此,要小心,要毫不犹豫地创建一个新的应用程序进行测试,而不是篡改现有的应用程序。唯一的例外是 showcase 数据库:如果出现问题,您可以通过删除数据库文件夹并重新启动 py4web 来重新创建它。这将使用所有示例数据重新创建数据库。
请注意,包含 python 提示符 >>> 的大多数代码片段也可以通过 py4web shell 直接执行。
这里是一个简单地示例,它使用 py4web 提供的 showcase 应用程序
>>> from apps.showcase.examples.models import db
>>> db.tables()
['auth_user', 'auth_user_tag_groups', 'person', 'superhero', 'superpower', 'tag', 'thing', 'user_token', 'dummy']
>>> rows = db(db.superhero.name != None).select()
>>> rows.first()
<Row {'id': 1, 'tag': <Set ("tag"."superhero" = 1)>, 'name': 'Superman', 'real_identity': 1}>
您还可以从零开始创建连接。为了简单起见,您可以使用 SQLite。当您切换后端数据库引擎时,数据库中的任何内容都不会改变。
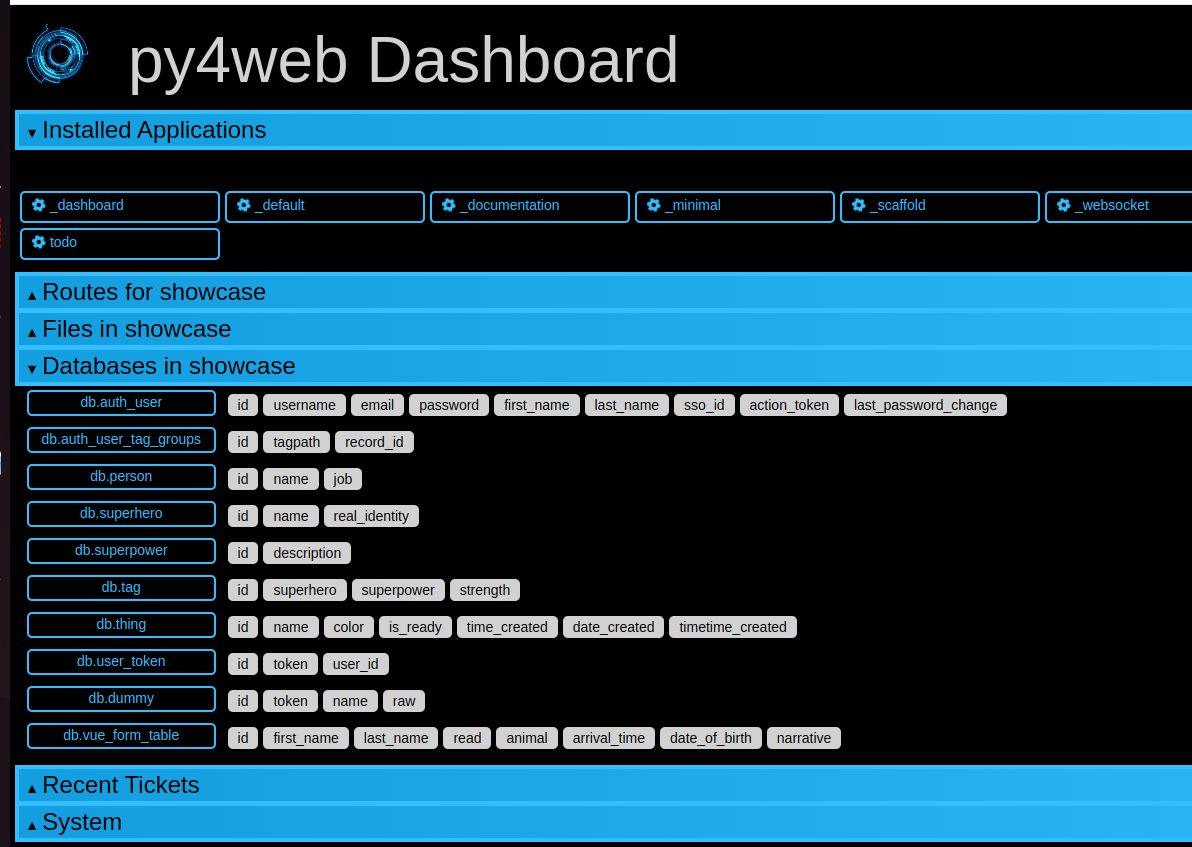
使用带有数据的 dashboard 应用程序
通常,您可以使用 dashboard 应用程序查看和修改特定应用程序的数据库。然而,这是危险的,因此出于安全原因,默认情况下这不适用于 showcase 应用程序。但是,如果你的 py4web 在本地(不暴露在公共网络中),你可以通过在文件 apps/showcase/__init__.py 中简单地添加以下行来启用它:
from .examples.models import db
这允许您以图形方式查看 showcase 应用程序内部的数据库:
DAL 的构造函数
基本用法:
>>> db = DAL('sqlite://storage.sqlite')
现在,连接了数据库,并且 连接 被存储在全局变量 db 中
您可以随时检索连接字符串。
>>> db._uri
sqlite://storage.sqlite
也可以获取数据库名称
>>> db._dbname
sqlite
连接字符串称为 _uri ,因为它是统一资源标识符的实例。
DAL 允许与同一数据库或不同数据库,甚至不同类型的数据库进行多个连接。目前,我们将假设存在一个数据库,因为这是最常见的情况。
DAL 的签名
DAL(uri='sqlite://dummy.db',
pool_size=0,
folder=None,
db_codec='UTF-8',
check_reserved=None,
migrate=True,
fake_migrate=False,
migrate_enabled=True,
fake_migrate_all=False,
decode_credentials=False,
driver_args=None,
adapter_args=None,
attempts=5,
auto_import=False,
bigint_id=False,
debug=False,
lazy_tables=False,
db_uid=None,
do_connect=True,
after_connection=None,
tables=None,
ignore_field_case=True,
entity_quoting=False,
table_hash=None)
连接字符串(参数 uri)
通过创建 DAL 对象的实例来建立与数据库的连接:
db = DAL('sqlite://storage.sqlite')
db 不是关键字;它是存储连接对象 DAL 的局部变量。你可以自由地给它起一个不同的名字。DAL 的构造函数至少需要一个参数,即连接字符串。连接字符串是唯一依赖于特定后端数据库的 py4web 代码。以下是受支持的特定类型的后端数据库的连接字符串示例(在所有情况下,我们假设数据库以 localhost 方式运行在其默认端口上,并命名为 “test” ):
数据库 |
连接字符串 |
|---|---|
SQLite |
|
MySQL |
|
PostgreSQL |
|
MSSQL (legacy) |
|
MSSQL (>=2005) |
|
MSSQL (>=2012) |
|
FireBird |
|
Oracle |
|
DB2 |
|
Ingres |
|
Sybase |
|
Informix |
|
Teradata |
|
Cubrid |
|
SAPDB |
|
IMAP |
|
MongoDB |
|
Google/SQL |
|
Google/NoSQL |
|
Google/NoSQL/NDB |
|
在 SQLite 中,数据库由单个文件组成。如果它不存在,则创建它。每次访问此文件时都会将其锁定。除了一个 sql.log 文件,对于每个表定义,还有一个名为 longhash_tablename.table 的附加文件。表定义文件在迁移过程中使用;如果出现问题,可以删除它们(它们将自动重新创建)。
对于 MySQL、PostgreSQL、MSSQL、FireBird、Oracle、DB2、Ingres 和 Informix 的情况,必须在 py4web 之外单独创建数据库 “test” 。 连接建立后,py4web 将恰当地创建、更改和删除表。
默认情况下,MySQL 只能处理由 1 到 3 个字节构成的 Unicode 字符,因此在 MySQL 连接字符串中末尾的
?set_encoding=utf8mb4将编码设置为UTF-8,这将避免在由 4 个字节组成的 Unicode 字符上出现Invalid utf8 character string:错误.在 Google/NoSQL 的情况下,选项
+ndb会启用 NDB。NDB 使用 Memcache 缓冲区读取经常访问的数据。这是完全自动的,在数据存储级别完成,而不是在 py4web 级别。也可以将连接字符串设置为
None。这种情况下,DAL 不会连接任何后端数据库,但是依然可以访问 DAL 的有关 API 进行测试。
有时,您可能还需要生成 SQL 语句,就像您有连接但没有实际连接到数据库一样。这可以通过以下方式完成:
db = DAL('...', do_connect=False)
在这种情况下,你可以调用 _select 、 _insert 、 _update 和 _delete 来生成 SQL 语句,但是不能调用 select 、 _insert 、 update 、 和 delete ;有关详细信息,请参阅 Generating raw SQL 。在大多数情况下,即使没有所需的数据库驱动程序,也可以使用 do_connect=False 。
请注意,py4web 默认数据库使用 utf8 字符编码。如果你使用编码不同的已有数据库,就必须使用 db_codec 参数选项改变设置:
db = DAL('...', db_codec='latin1')
否则,你将收到 UnicodeDecodeError tickets 。
连接池
DAL 构造函数的一个常用参数是 pool_size,其默认值是 0 。
由于为每个请求建立新的数据库连接相当缓慢,所以 py4web 实现了一种连接池机制。一旦建立了一个连接,页面被提供并且事务完成后,这个连接不会被关闭,而是进入池中。当下一个请求到达时,py4web 会尝试从池中回收连接,并将其用于新事务。如果池中没有可用连接,那么再建立新的连接。
py4web 刚启动时,连接池总是空的。池中的连接数量增长到 pool_size 的值和并发请求的最大数量中的最小值。这意味着,如果 pool_size=10 ,但我们的服务器从未收到超过5个并发请求,那么池中实际的连接数量只会增长到 5。如果 pool_size=0 ,则不使用连接池。
池中的连接在线程之间按顺序共享,也就是说,它们可能由两个不同但不同时的线程使用。每个 py4web 进程只有一个池。
pool_size 参数会被 SQLite 和 Google App Engine 忽略。SQLite 忽略了连接池,因为连接池对 SQLite 不会产生任何好处。
连接失败(attempts 参数)
如果 py4web 无法连接到数据库,它会等待 1 秒后重试,默认情况下会在声明失败之前最多重试 5 次。在有连接池的情况下,数据库端可能会关闭在一段时间内保持打开但未使用 的连接。由于重试功能,py4web 会尝试重新建立这些断开的连接。尝试次数通过 attempts 参数设置。
懒惰表
设置 lazy_tables = True ,可以显著提高性能(但在 py4web 中不会)。这意味着表的创建被推迟,直到表被实际引用。
警告
你永远不应该在 py4web 中使用懒惰表。那既没优势也没必要,还可能存在并发问题。
“无模型” 应用程序
在 py4web 中,定义 DAL 表的代码通常位于 models.py 文件中。因为 models.py 在 actions 之外,所以只在 py4web 启动时,它才被运行一次。
但是,依然可以在 actions 内部按需定义 DAL 表。这被 py4web 社区称为 “无模型” 开发。
使用 “无模型” 方式,您需要负责完成所有内置的管理任务。需要时,调用表定义,并提供数据库连接作为参数传递。此外,请记住可维护性:其他 py4web 开发人员希望在 models.py 文件中找到数据库及表的定义。
多个数据库
DAL(...) 的第一个参数可以是 URI 列表。在这种情况下,py4web 试图连接到每个 URI。其主要目的是处理多个数据库服务器,并在它们之间分配工作负载。以下是一个典型的用例:
db = DAL(['mysql://...1', 'mysql://...2', 'mysql://...3'])
在这种情况下,DAL 尝试连接到第一个,如果失败,它将尝试第二个和第三个。这也可用于在数据库主从配置中分配负载。
保留的关键字
check_reserved 告诉构造函数,根据后端数据库中保留的 SQL 关键字检查表名和列名,其默认值为 None。
check_reserved 的值是一个包含数据库后端适配器名称的字符串列表。
适配器名称与 DAL 连接字符串中使用的名称相同。因此,如果你想检查 PostgreSQL 和 MSSQ L,那么你的 db 定义如下:
db = DAL('sqlite://storage.sqlite', check_reserved=['postgres', 'mssql'])
DAL 将按照列表中的顺序检查关键字。
有两个额外的选项 “all” 和 “common”。如果指定 “all” ,它将检查所有已知的 SQL关键字。如果指定 “common”,它将只检查常见的 SQL 关键字,如 SELECT 、 INSERT 、 UPDATE 等。
对于支持的后端,您还可以指定是否也要检查非保留的 SQL 关键字。在这种情况下,您应该在数据库适配器名称后附加 _nonreserved 。例如:
check_reserved=['postgres', 'postgres_nonreserved']
以下后端数据库支持保留字检查。
数据库 |
check_reserved 参数 |
|---|---|
PostgreSQL |
|
MySQL |
|
FireBird |
|
MSSQL |
|
Oracle |
|
数据库中的引号和大小写设置
DAL 中默认启用 SQL 实体的引号,即
entity_quoting = True
这样,DAL 生成的 SQL 中会自动把标识符放在一对引号内。在 SQL 级别,关键字和未加引号的标识符不区分大小写,因此加引号的 SQL 标识符会使其区分大小写。
请注意,根据 SQL 标准,后端引擎应始终将未引用的标识符处理为小写,但并非所有引擎都符合此标准(例如 PostgreSQL 默认处理为大写)
默认情况下,DAL 也忽略字段大小写,要更改此用法,请如下设置:
ignore_field_case = False
为了确保在 python 和 DB 模式中使用相同的名称,您必须做好上述两个设置。以下是一个示例:
db = DAL(ignore_field_case=False)
db.define_table('table1', Field('column'), Field('COLUMN'))
query = db.table1.COLUMN != db.table1.column
建立安全连接
有时,有必要(并建议)使用 安全连接 连接到数据库,特别是如果数据库与应用程序不在同一服务器上。在这种情况下,您需要将其他参数传递给数据库驱动程序。有关详细信息,请参阅数据库驱动程序文档。
对于带有 psycopg2 的 PostgreSQL ,它应该看起来像这样:
DAL('postgres://user_name:user_password@server_addr/db_name',
driver_args={'sslmode': 'require', 'sslrootcert': 'root.crt',
'sslcert': 'postgresql.crt', 'sslkey': 'postgresql.key'})
其中参数 sslrootcert 、 sslcert 和 sslkey 应包含文件的完整路径。您应该参考 PostgreSQL 文档,了解如何配置 PostgreSQL 服务器以接受安全连接。
DAL 构造函数的其它参数
数据库文件夹的位置
folder 设置创建迁移文件的位置(有关详细信息,请参阅 Migrations )。默认情况下,它在 py4web 中自动设置为数据库自身所在的那个文件夹,但在 py4web 外使用 DAL 时必须指定它。
请注意,这对于 SQLite 数据库通常是必要的,否则您将隐式选择内存中的数据库(其中文件夹和迁移没有任何意义)。因此,下面的构造函数具有相同的含义:
db = DAL('sqlite://storage.sqlite') # folder parameter not specified
db = DAL('sqlite:memory') # in memory database
默认迁移设置
DAL 构造函数的迁移设置是布尔值,会影响默认值和全局行为(详情请参见 Migrations )
migrate = True 为所有表设置为开启默认迁移行为
fake_migrate = False 为所有表设置 模拟迁移 行为(False ,表示进行“真实迁移”,不仅更新 DAL 结构,也会同步更新数据库的表结构;True ,表示进行 “模拟迁移”,仅更新 DAL 结构,不对数据库进行任何修改)
migrate_enabled = True 设置为 False ,将禁用所有迁移
fake_migrate_all = False 设置为 True,对所有表执行 “模拟迁移”
commit 和 rollback
在 py4web 发出 commit 命令之前,insert、 truncate、 delete 和 update 操作实际上不会被提交。 create 和 drop 操作可能立即执行,具体取决于数据库引擎。
如果你在 action.uses() 装饰器中传递 db 参数,那么你不需要在控制器中调用 commit,它会自动为你完成(如果你使用 authenticated 或 unauthenticated 装饰器,也是一样的。)
小技巧
始终在 action.uses 装饰器中添加 db 参数(或使用 authenticated 或 unauthenticated 装饰器时)。否则,您必须在每个 define_table() 中和每个表的操作(insert()、update()、delete())中添加 db.commit()
因此,在 py4web 的 actions 中,通常不需要显式调用 commit 或 rollback ,除非您需要更精细的控制。
但是,如果你使用 shell 执行命令,就需要手动显示地执行 commit:
>>> db.commit()
要检查它,让我们插入一条新记录:
>>> db.person.insert(name="Bob")
2
现在 回滚,即忽略自上次提交以来的所有操作:
>>> db.rollback()
如果重新插入数据,计数器将再次被设置为 2,因为前面地插入被回滚了。
>>> db.person.insert(name="Bob")
2
models、 views 和 controllers 中的代码被封装在 py4web 代码中,看起来像这样(伪代码):
try:
execute models, controller function and view
except:
rollback all connections
log the traceback
send a ticket to the visitor
else:
commit all connections
save cookies, sessions and return the page
“Table” 的构造函数
表 (Table),由 DAL 中的 define_table() 来定义。
define_table 的签名
define_table() 的签名是:
define_table(tablename, *fields, **kwargs)
它接受一个必须有的表名和可选数量的 Field 实例(也可以没有)。 除了 Field 对象,您还可以传递一个 Table (或子类)对象,这将克隆并添加所有字段(但 “id” 除外)到定义的表中。其他可选关键字参数包括: rname 、 redefine 、 common_filter 、 fake_migrate 、 fields 、 format 、 migrate 、 on_define 、 plural 、 polymodel 、 primarykey 、 sequence_name 、 singular 、 table_class 和 trigger_name,下文将对这些进行讨论。
例如:
>>> db.define_table('person', Field('name'))
<Table person (id, name)>
这同时定义、存储并返回一个被称为 “person” 的 Table 对象,里面包含一个 “name” 字段(列)。这个对象也能够通过 db.person 访问,因此不需要捕获 define_table() 的返回值。
id : 关于主键的说明
不要声明一个名为 “id” 的字段,因为它是由 py4web 创建的。默认情况下,每个表都有一个名为 “id” 的字段。它是一个自动递增的整数字段(通常从 1 开始),这用于交叉引用和确保每条记录是唯一的,因此 “id” 是主键。(注意:从 1 开始的 id 计数器是由后端数据库决定的。例如,这不适用于 Google App Engine NoSQL。)
您可以选择定义一个类型为 “id” 的字段,py4web 会将此字段用作自动递增的 id 字段。不建议这样做,除非访问的旧数据库表具有名称不是 id 的主键。在某些限制下,您还可以设置 primarykey 参数来使用不同的主键。
plural 和 singular
由于 pyDAL 是一个通用的 DAL,因此它包括 plural 和 singular 属性来引用表名,以便外部元素可以使用表的正确名称。
redefine
表只能定义一次,但是您可以强制 py4web 重新定义一个已存在的表:
db.define_table('person', Field('name'))
db.define_table('person', Field('name'), redefine=True)
如果表定义有变化,那么 “重新定义表” 会导致 “迁移”。
format: 代表记录的显示格式
这是可选的,但建议使用 format 参数指定代表记录的显示格式。
db.define_table('person', Field('name'), format='%(name)s')
或者
db.define_table('person', Field('name'), format='%(name)s %(id)s')
或者更复杂的情况是使用一个函数:
db.define_table('person', Field('name'),
format=lambda r: r.name or 'anonymous')
format 属性被用于两个目的:
在 select/option 下拉菜单中表示引用的记录。
为引用此表的所有字段设置
db.othertable.otherfield.represent属性。这意味着Form构造函数不会按 id 显示引用的记录,而是以预设的格式表示。
rname: 真实名称
rname 为表设置数据库后端名称。这使得 py4web 中定义的表名成为别名,而 rname 是构建后端查询时使用的真实名称。仅举一个例子, rname 可用于为 MSSQL 提供完全限定表名,以访问属于服务器上其他数据库的表: rname = 'db1.dbo.table1'
primarykey: 支持已有的旧表
primarykey 有助于支持具有现有主键的遗留表,甚至是多字段组成主键的表。请参见 Legacy databases and keyed tables 。
migrate, fake_migrate
migrate 设置 “表” 的 “迁移选项” ,migrate 默认值是 True ,表示 web 应用启动时自动对比模型与数据库中的表结构,自动添加新字段(不会修改已有字段的某些属性,也不会删除已有不用的字段)。fake_migrate 设置是否进行虚拟迁移,默认值是 False ,即不实际修改数据库结构,仅更新应用中的模型数据。详情请参阅 Migrations
table_class
如果定义了一个 pydal.objects.Table 的子类,你可以设置给这个参数;这允许你扩展和重写方法,例如:
from pydal.objects import Table
class MyTable(Table):
...
db.define_table(..., table_class=MyTable)
sequence_name
自定义表序列的名称(如果数据库支持)。可以创建 SEQUENCE(从 1 开始,每次递增 1),也可以将其用于具有自定义序列的旧表。
请注意,默认情况下 py4web 会在必要时自动创建序列。
trigger_name
与 sequence_name 相关。与某些不支持自动递增数字字段的后端相关。
polymodel
用于 Google App Engine 。
on_define
on_define 是一个在实例化 lazy_table 时触发的回调,即使表不是 “懒惰” 的,它仍会被调用。这允许对表进行动态更改,而不会失去延迟实例化的优点。
例如:
db = DAL(lazy_tables=True)
db.define_table('person',
Field('name'),
Field('age', 'integer'),
on_define=lambda table: [
table.name.set_attributes(requires=IS_NOT_EMPTY(), default=''),
table.age.set_attributes(requires=IS_INT_IN_RANGE(0, 120), default=30) ])
注意,这个例子展示了如何使用 on_define ,但实际上是没必要的。简单的 requires 参数值可以添加到 Field 的定义中,而表仍会保持 “懒惰”。然而, requires 以 Set 对象作为第一个参数的话,如 IS_IN_DB,将发出类似 db.sometable.somefield == some_value 的查询,这会导致 sometable 提前按定义被创建。这种情况下,就要保留 on_define 。
向字段和表添加属性
如果需要向字段添加自定义的属性,只需简单地这样做:db.table.field.extra = {}
“extra” 不是一个关键字;现在,它是一个被附加到字段对象的自定义的属性。对于表也可以这样处理,但是表的自定义属性必须以下划线开始,以避免与字段发生命名冲突。
db.table._extra = {}
已有的数据库和指定主键的表
在某些情况下,py4web 可以连接到已有的数据库
最简单的方法是满足以下条件:
每个表都必须有一个名为 “id” 的唯一自动递增的整数字段。
必须仅使用 “id” 字段引用记录。
访问现有表(即不是由 py4web 在当前应用程序中创建的表)时,始终设置参数 migrate=False。
如果旧表有一个自动递增的整数字段,但它没有被命名为 “id” ,py4web 仍然可以访问它,但表定义必须用 “id” 类型声明自动递增字段(即使用 Field('...', 'id') )。
最后,如果遗留表使用的主键不是自动递增的 id 字段,则可以使用 “指定主键的表”,例如:
db.define_table('account',
Field('accnum', 'integer'),
Field('acctype'),
Field('accdesc'),
primarykey=['accnum', 'acctype'],
migrate=False)
primarykey是构成主键的字段名列表。即使未指定,所有主键字段都被设置为
NOT NULL。“指定主键的表” 只能引用其它 “指定主键的表” 。
引用字段必须使用
reference tablename.fieldname格式。update_record函数不适用于 “指定主键的表” 的数据行。
目前, “指定主键的表” 仅支持 DB2、MSSQL、Ingres 和 Informix ,但会继续添加其他引擎。
在撰写本文时,我们无法保证 primarykey 属性适用于每个现有的遗留表和每个支持的数据库后端。为了简单起见,如果可能的话,我们建议创建一个具有自动递增 id 字段的数据库视图。
“Field” 的构造函数
下面是 “Field” 的构造函数的默认值
Field(fieldname, type='string', length=None, default=DEFAULT,
required=False, requires=DEFAULT,
ondelete='CASCADE', notnull=False, unique=False,
uploadfield=True, widget=None, label=None, comment=None,
writable=True, readable=True, searchable=True, listable=True,
update=None, authorize=None, autodelete=False, represent=None,
uploadfolder=None, uploadseparate=None, uploadfs=None,
compute=None, filter_in=None, filter_out=None,
custom_qualifier=None, map_none=None, rname=None)
其中,DEFAULT 是个特殊的值,它允许参数的值是 None。
并非所有的参数对每个字段都有意义。length 仅适用于 “string” 类型的字段。uploadfield 、 authorize 和 autodelete 仅适用于 “upload” 类型的字段。ondelete 仅适用于 “reference” 或 “upload” 类型的字段。
length设置 “string”、 “password” 或 “upload” 字段的最大长度。如果未指定length,则使用默认值,但不能保证默认值向后兼容。 为了避免升级时产生未知的 “迁移”,我们建议您始终指定 “string”、 “password” 或 “upload” 字段的长度。default设置字段的 “默认值”。当插入数据但未明确指定字段值的时候,就使用 “默认值”。它还用于使用Form从 “Table” 构建预填充的表单。请注意,默认值不是固定值,它可以是一个函数(包括 lambda 函数),它为字段返回适当类型的值。在这种情况下,即使在单个事务中插入了多条记录,该函数也会为插入的每条记录调用一次。required告知 DAL,如果没有明确指定字段的值,那么不允许在表内插入数据。requires一个 验证器,或是多个验证器的列表。DAL 中不使用这里指定的验证器,相反,它们在Form里面被使用。( 表单(Forms) 章节由更好的解释)在后面的 字段的类型和验证器 部分,给出了各种已知字段类型的默认验证器。详细内容请参考 web2py 框架中 pyDAL 模块的验证器备注
requires=...是在 form 级别被强制执行,而required=True在 DAL(插入)级别被强制执行。此外,在数据库级别强制执行notnull、unique和ondelete。虽然它们有时看起来是多余的,但在使用 DAL 编程时保持这种区别很重要。rname为字段提供 “真实名称”,一个数据库适配已知的字段名称;当使用字段时,发送到数据库的是 “rname” 值。字段的 py4web 名称会失效,就变成了字段的别名。ondelete被转换为 “ON DELETE” SQ L语句。默认情况下,它设置为 “CASCADE”。这告诉数据库,当它删除记录时,还应该删除引用它的所有记录。若要禁用此功能,请将ondelete设置为 “NO ACTION” 或 “set NULL” 。notnull=True被转换为 “NOT NULL” SQ L语句。这阻止数据库为字段插入 null 值。unique=True被转换为 “UNIQUE” SQ L语句,它确保字段的值在表里是唯一的。这在数据库级别强制执行。uploadfield仅适用于 “upload” 类型的字段。“upload” 类型的字段存储已保存在其它地方的文件名,默认是在文件系统中 “应用程序” 的 “uploads/” 目录下。如果uploadfield设置为 True,那么文件被存储在同一个表的二进制字段内,uploadfield的值是二进制字段的名称。稍后,在 More on uploads 中进行更详细地讨论。uploadfolder必须被设置为一个存储已上传文件的位置。 scaffolding 应用程序定义了一个文件夹settings.UPLOAD_FOLDER,它指向apps/{app_name}/uploads,因此,你能这样设置:Field(... uploadfolder=settings.UPLOAD_FOLDER)。如果设置
uploadseparate为 True,那么将会把文件上传到 uploadfolder 指定的文件夹下的不同的子文件夹下。这是为了避免同一文件夹/子文件夹下有太多文件而优化的。注意:如果不断开现有已上传的文件链接,则无法将uploadseparate的值从 True 更改为 False。pydal 要么使用单独的子文件夹,要么不使用。在文件上传后的更改行为将阻止 pydal 检索到这些文件。如果发生这种情况,可以移动文件并修复问题,但这里没有描述。uploadfs允许你为上传文件指定一个不同的文件系统,包括 Amazon S3 存储系统或者远程 SFTP 存储系统。
您需要安装 PyFileSystem 才能正常工作。
uploadfs必须指向 PyFileSystem。
autodelete确定在删除引用文件的记录时是否应删除相应的上传文件,这仅适用于 “upload” 字段。但是,因 CASCADE 操作导致由数据库本身删除记录时不会触发 py4web 的自动删除。label是一个字符串(或辅助程序,或可以序列化为字符串的东西,它包含自动生成的表单中用于此字段的标签),该字符串包含与此字段相关联的说明文字,且会显示在自动生成表单的输入框右侧。writable声明一个字段的值在表单中是否可写(编辑)。readable声明一个字段的值在表单中是否可读(是否显示)。如果一个字段既不可读也不可写,它将不会在 create 或 update 类型的表单中显示。update包含更新记录时这个字段的默认更新的值。compute是一个可选函数。插入或更新记录后,compute 函数将被执行,然后以函数的返回值作为字段的值。当前记录以一个dict的形式被传给 compute 函数时,被传递的 “字典” 里不包含这个 compute 字段的当前值,也不包含其它 compute 字段。authorize可用于要求对相应字段进行访问控制,仅适用于 “upload” 字段。这将在身份验证和授权的部分进行更详细的讨论。widget注意,在 py4web 中,字段定义 不要使用 widget 参数 。(这是 web2py 的特性,而且在 py4web 里未被使用)请参阅后面的 小部件represent可以是 None,也可以指向一个函数,该函数接受字段当前值并返回字段值的替代表示形式。
线程安全和字段属性
尽管 py4web 和 web2py 使用相同的 pyDAL,但是由 py4web 的核心架构导致了存在重要差异。在 py4web 中,只有以下 Field 属性可以在 action 中更改:
readablewritabledefaultfilter_infilter_outlabelupdaterequireswidgetrepresent
在调用每个 action 之前,这些值都将重置为原始值。所有其他 Field、 DAL 和 Table 都是全局的、非线程安全的。
这种限制的存在是因为 py4web 只在启动时执行表定义,而 web2py 在每次请求时都会重新定义表。这使得 py4web 比 web2py 快得多,但你需要小心,因为修改 actions 中的非线程安全属性可能会导致冲突和错误。
字段的类型和验证器
类型 |
默认验证器 |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Decimal 要求值是 Decimal 对象,返回值也是,在 Python 的 decimal 模块中有定义。SQLite 不处理 decimal 类型,因此在 SQLite 内部将其视为 double。(n,m)分别是总数和小数点后的位数。
big-id 和 big-reference 仅有一些数据库引擎支持,并且是实验性的。它们通常不用作字段类型,除非用于已有的旧表,但是,DAL 构造函数有一个 bigint_id 参数,当设置为 True 时,id 字段和 reference 字段分别为 big-id 和 big-reference 。
list:<type> 字段是特殊的,因为它们被设计为利用 NoSQL 上的某些非规范化特性(在 Google App Engine NoSQL 的情况下,字段类型 ListProperty 和 StringListProperty),并将它们移植到所有其他支持的关系数据库中。在关系数据库中,列表存储为文本字段。这些项用 | 分隔,而字符串项中的每个 | 都转义为 || 。它们在 list:<type> 和 contains 中讨论。
json 字段类型的含义相当直观。它可以存储任何可 JSON 序列化的对象。该字段类型专为 MongoDB 设计以实现特定适配,同时为确保可移植性,也反向兼容了其他数据库适配器。
blob 字段同样具有特殊性。默认情况下,二进制数据在存入实际数据库字段之前会先进行 Base64 编码,提取数据时则会进行解码。这种处理方式的缺点是,会导致 Blob 字段占用比实际所需多 33% 的存储空间;但优点在于,能让数据传输摆脱后端特定转义规则的限制,实现解耦。
在运行时修改字段和表
字段和表的大部分属性都可以在它们的定义后进行修改。
>>> db.define_table('person', Field('name', default=''), format='%(name)s')
<Table person (id, name)>
>>> db.person._format = '%(name)s/%(id)s'
>>> db.person.name.default = 'anonymous'
请注意,表的属性通常以下划线作为前缀,以避免与可能的字段名冲突。
您可以由给定数据库连接列出已定义的表:
>>> db.tables
['person']
您可以查询表的类型:
>>> type(db.person)
<class 'pydal.objects.Table'>
你可以使用不同的语法访问表:
>>> db.person is db['person']
True
您还可以由给定的表列出已定义的字段:
>>> db.person.fields
['id', 'name']
同样,您可以通过多种等效的方式依据字段名称访问字段:
>>> type(db.person.name)
<class 'pydal.objects.Field'>
>>> db.person.name is db.person['name']
True
给定一个字段,您可以访问其定义中的属性集:
>>> db.person.name.type
string
>>> db.person.name.unique
False
>>> db.person.name.notnull
False
>>> db.person.name.length
32
包括它所属的表、表名称和所属的连接
>>> db.person.name._table == db.person
True
>>> db.person.name._tablename == 'person'
True
>>> db.person.name._db == db
True
字段也有方法。其中一些用于构建查询,我们稍后会看到它们。字段对象的一种特殊方法是 validate ,它调用字段的验证器。
>>> db.person.name.validate('John')
('John', None)
验证器发回一个元组 (value, error)。如果验证成功通过 error 的值是 None。
“上传” 的更多内容
考虑以下模型:
db.define_table('myfile',
Field('image', 'upload', default='path/to/file'))
在 “upload” 字段的情况下,可选择将默认值设为一个路径(可以是绝对路径,也可以是相对于当前应用文件夹的相对路径);对于包含未指定路径的图片的每条新记录,系统会自动为其分配该默认值。
请注意,这样多条记录可能会引用同一个默认图像文件,这在启用了 autodelete 的字段上可能会出现问题。当您不想允许图像字段重复(即多个记录引用同一文件),但仍想为 “upload” 设置默认值时,就需要一种方法为每条包含未指路径的图像的新记录复制默认文件。这可以通过使用引用默认文件的 “类文件对象” 作为字段的 default 参数值,甚至可以使用:
Field('image', 'upload', default=dict(data='<file_content>', filename='<file_name>'))
通常,“插入” 是通过 Form 自动处理的,但有时您已经在文件系统上拥有该文件,并希望以编程方式上传它。这可以通过以下方式完成:
with open(filename, 'rb') as stream:
db.myfile.insert(image=db.myfile.image.store(stream, filename))
也可以以更简单的方式插入文件,并使插入方法自动调用 store :
with open(filename, 'rb') as stream:
db.myfile.insert(image=stream)
在这种情况下,文件名是从流对象(如果可用)中获得的。
上传字段对象的 store 方法接受一个文件流和一个文件名。它使用文件名来确定文件的扩展名(文件类型),为文件创建一个新的临时名称(根据 py4web 上传机制),并将文件内容加载到这个新的临时文件中(若无额外说明,则自动在 uploads 文件夹下保存临时文件)。它返回新的临时名称,然后将其存储在 db.myfile 表的 image 字段中。
请注意,如果文件要存储在关联的二进制字段而不是文件系统中,则 store 方法不会将文件插入二进制字段中(因为 store 在插入之前被调用),因此必须将文件显式插入二进制字段:
db.define_table('myfile',
Field('image', 'upload', uploadfield='image_file'),
Field('image_file', 'blob'))
with open(filename, 'rb') as stream:
db.myfile.insert(image=db.myfile.image.store(stream, filename),
image_file=stream.read())
retrieve 方法与 store 的作用相反。
当上传的文件存储在文件系统中时(如普通的 Field('image', 'upload') 情况),代码:
row = db(db.myfile).select().first()
(filename, fullname) = db.myfile.image.retrieve(row.image, nameonly=True)
检索用户在上传时看到的原始文件名(文件名)和存储文件的名称(全名,带有相对于应用程序文件夹的路径)。而一般地调用:
(filename, stream) = db.myfile.image.retrieve(row.image)
将检索原始文件名(文件名)和类文件对象,以准备访问上传文件数据(流)。
请注意,在上传的文件存储在文件系统上的情况下,
retrieve返回的流是一个真实的文件对象。在这种情况下,记得在完成后调用stream.close()关闭文件。
这里的例子是 retrieve 的安全用法:
from contextlib import closing
import shutil
row = db(db.myfile).select().first()
(filename, stream) = db.myfile.image.retrieve(row.image)
with closing(stream) as src, closing(open(filename, 'wb')) as dest:
shutil.copyfileobj(src, dest)
迁移
使用我们示例的表定义:
db.define_table('person')
define_table 检查相应的表是否存在。如果没有,它将生成创建表的 SQL 语句并执行。如果表确实存在,但与正在定义的表不同,它将生成变更表的 SQL 语句并执行。如果字段的类型发生了变化,但名称没有变化,它将尝试转换数据(如果你不想这样做,你需要重新定义表两次,第一次是让 py4web 删除字段,第二次是添加新定义的字段,以便 py4web 可以创建新类型的同名字段)。如果该表存在并且与当前定义匹配,它将保持原样。在所有情况下,它都会创建表示表的 db.person 对象。
我们说的 “迁移” 指的就是这种行为。py4web 在文件 “sql.log” 中记录所有迁移和迁移尝试。
备注
默认情况下, py4web 的日志文件和用到的所有其它迁移文件都保存在 “app/databases” 目录下。你可以通过设置 DAL 构造函数的 folder 参数来改变默认的保存位置。要设置一个不同的日志文件名,例如 “migrate.log” ,你可以设置为 db = DAL(..., adapter_args=dict(logfile='migrate.log')) 。
define_table 的第一个参数始终是表名。其他未命名的参数是字段。该函数还接受一个名为 “migrate” 的可选关键字参数:
db.define_table('person', ..., migrate='person.table')
migrate 的值是 py4web 存储此表内部迁移信息的文件名。这些文件非常重要,当相应的表存在时,不应将其删除。如果表已被删除,但相应的文件仍然存在,则可以手动将其删除。默认情况下,migrate 设置为 True。这会导致 py4web 根据连接字符串的哈希生成文件名。如果 migrate 设置为 False,则不执行迁移,py4web 则会假设该表存在于数据存储中,并且它至少包含 define_table 中列出的字段。
同一应用程序中不可能有两个表对应同一个迁移文件名。
DAL类也接受一个 “migrate” 参数,该参数决定了调用 define_table 时 migrate 的默认值。例如,
db = DAL('sqlite://storage.sqlite', migrate=False)
每当在没有 migrate 参数的情况下调用 db.define_table 时,migrate 的默认值将被设置为 False 。
备注
迁移时,py4web 会添加新列、删除列或改变列的类型(SQLite 除外)。 py4web 不会在迁移时改变其它属性,例如不改变 default 、 unique 、 notnull 或 ondelete 的值。
可以一次禁用所有表的迁移
db = DAL(..., migrate_enabled=False)
当两个应用程序共用一个数据库时,建议这样做。两个应用程序中应该只有一个启用执行迁移,另一个应该禁用。
修复损坏的迁移
迁移会遇到两种常见的问题,下面是一些从中恢复的方法。
SQLite 存在一个特定的问题。SQLite 不强制执行列类型,也不能删除列。这意味着,如果你有一个 string 类型的列并将其删除,那么它并没有真正被删除。如果你用不同的类型(例如 datetime )再次添加同名的列,你最终会得到一个类型是 string 的列(这不是实际想要的结果)。py4web 不会抱怨这一点,因为它不知道数据库中有什么,直到尝试检索记录时导致失败。
如果在某些解析函数中检索记录时,py4web 返回错误,很可能是由于上述问题导致列中的数据损坏。
这种情况的解决方案包括更新表的所有记录,并将相关列中的值更新为 None。
另一个问题更为普遍,但在 MySQL 中更为常见。MySQL 不允许一个事务中有多个 ALTER TABLE 。这意味着 py4web 必须将复杂的事务分解为更小的事务(一次一个 ALTER TABLE ),并一次提交一个事务。因此,复杂事务的一部分可能被提交,而另一部分失败,导致 py4web 处于错误状态。为什么部分交易会失败?例如,因为它涉及更改表并将 string 列转换为 datetime 列,py4web 会尝试转换数据,但字符串无法转换成日期。py4web 怎么办?它对数据库中实际存储的表结构感到困惑。
这种情况的解决方案包括启用虚假迁移:
db.define_table(...., migrate=True, fake_migrate=True)
这将依据表定义重建 py4web 中相关表的元数据。尝试多个表定义,看看哪一个有效(一个是在迁移失败之前,另一个是迁移失败之后)。一旦成功,就移除 fake_migrate=True 参数。
在尝试修复迁移问题之前,谨慎的做法是复制 “yourapp/databases/*.table” 文件。
也可以一次修复迁移中的所有问题表:
db = DAL(..., fake_migrate_all=True)
如果模型描述了数据库中不存在的表,这也会失败,但它可以帮助缩小问题的范围。
迁移控制摘要
此处的伪代码总结了各种迁移参数的逻辑:
if DAL.migrate_enabled and table.migrate:
if DAL.fake_migrate_all or table.fake_migrate:
perform fake migration
else:
perform migration
“Table” 的方法
insert
给定一个表,你可以插入记录
>>> db.person.insert(name="Alex")
1
>>> db.person.insert(name="Bob")
2
Insert() 返回唯一表示每条被插入记录的 “id” 。
您可以对表调用 truncate() ,即删除所有记录并重置 id 的计数器。
>>> db.person.truncate()
现在,如果你再插入一条记录,计数器又会重新从 1 开始(这是与后端数据库相关的,不适用于 Google NoSQL):
>>> db.person.insert(name="Alex")
1
注意,你可以给 truncate 一个参数,例如,你可以告诉 SQLite 让 id 计数器重新开始。
>>> db.person.truncate('RESTART IDENTITY CASCADE')
参数是原始的 SQL 语句,因此这只对特定引擎有效。
py4web 也提供一个 bulk_insert() 方法
>>> db.person.bulk_insert([{'name': 'Alex'}, {'name': 'John'}, {'name': 'Tim'}])
[3, 4, 5]
它以要插入的字段值的字典组成的列表为参数,并一次执行插入多个记录。它返回插入记录的 “id” 值的列表。在支持的关系数据库上,与循环和执行单个插入操作相比,使用此函数没有优势,但在 Google App Engine NoSQL 上,有一个主要的速度优势。
Query, Set, Rows
让我们再次考虑借用之前定义(并删除)的表,并插入三条记录:
>>> db.define_table('person', Field('name'))
<Table person (id, name)>
>>> db.person.insert(name="Alex")
1
>>> db.person.insert(name="Bob")
2
>>> db.person.insert(name="Carl")
3
你可以把 “表” 存储到一个变量。例如,使用变量 “person” ,你可以这样:
>>> person = db.person
你也可以把 “字段” 存储到一个变量。例如,使用变量 “name” ,你可以这样:
>>> name = person.name
你甚至可以构建一个查询(使用 == 、!= 、< 、 > 、 <= 、 >= 、 .like() 、 .belongs() 等运算符),然后把这个查询放在一个名为 “q” 的变量里,例如:
>>> q = name == 'Alex'
当你使用查询调用 db 时,就定义了一个由多个记录组成的集合。你能把它存储在名为 “s” 的变量中,例如:
>>> s = db(q)
请注意,到目前为止还没有执行任何数据库查询。DAL + Query 只是在此数据库中定义一组与查询相匹配的记录。py4web 从查询中确定涉及哪些表,事实上,不需要显示指定表。
update_or_insert
有时,只有当没有与要插入的值相同的记录时,才需要执行插入操作。这可以通过以下方式完成
db.define_table('person',
Field('name'),
Field('birthplace'))
db.person.update_or_insert(name='John', birthplace='Chicago')
只有当数据库中没有出生在 Chicago 且名为 John 的用户时,才会插入该记录。
您可以指定使用哪些值作为键来确定记录是否存在。例如:
db.person.update_or_insert(db.person.name == 'John',
name='John',
birthplace='Chicago')
如果有姓名为 John 的记录,那么他的出生地将被更新,否则将创建新的记录。
上例中的匹配记录的条件标准是单一的一个字段。它也可以是一个查询,例如
db.person.update_or_insert((db.person.name == 'John') & (db.person.birthplace == 'Chicago'),
name='John',
birthplace='Chicago',
pet='Rover')
validate_and_insert, validate_and_update
除了在执行插入之前调用字段的验证器,函数
ret = db.mytable.validate_and_insert(field='value')
的作用非常像
id = db.mytable.insert(field='value')
如果验证不通过,则退出。如果验证不合格,则可以在 ret["errors"] 中找到错误。 ret["errors"] 保存了一个键值映射,其中每个键都是验证失败的字段名,键的值是验证错误的结果(很像 form["errors"] )。如果通过,则新记录的 id 为 ret["id"] 。请注意,通常验证是由表单处理逻辑完成的,因此很少需要单独调用此函数。
类似地,除了在执行更新之前调用字段的验证器。函数
ret = db(query).validate_and_update(field='value')
的作用非常像
num = db(query).update(field='value')
请注意,这仅在查询涉及单个表时有效。更新记录的数量可以在 ret["updated"] 中找到,而错误在 ret["errors"] 中。
drop
最后,你可以删除表,表中的所有数据也都将丢失:
db.person.drop()
QueryBuilder() 查询生成器
你能使用自然语言生成 DAL 查询。这可以像下面这样做:
from py4web import DAL, Field
from pydal import QueryBuilder, QueryParseError
db = DAL("sqlite:memory")
db.define_table("thing", Field("name"), Field("solid", "boolean"))
builder = QueryBuilder(db.thing)
query = builder.parse('name is equal to Chair')
rows = db(query).select()
合法的表达式示例如下:
name is null
name is not null
name == Chair
name is Chair
name is equal Chair
name is equal to Chair
name is equal to "Chair"
name lower is equal to Chair
not name lower is equal to Chair
not (name lower is equal to Chair)
name == Chair or name == Table
name starts with C and name contains air
name in Chair, Table, Glass
name belongs Chair, Table, "Glass Top"
solid is true
solid is false
请注意,引号是可选的,仅适用于值。您可以使用括号进行分组。失败时,它会抛出QueryParseError 异常。您可以将可选参数传递给 QueryBuilder 以实现国际化(例如意大利语):
builder = QueryBuilder(db.thing,
field_aliases={"id": "id", "nome": "name"},
token_aliases={"non è nullo": "is not null", "è uguale a": "=="})
query = builder.parse('nome non è nullo')
query = builder.parse('nome è uguale a Tavolo')
如果未提供 field_aliases 参数,只有 readable 字段能被查询到。如果提供了 field_aliases 参数,则只有明确指定的字段能被查询到。
当然,您可以使用翻译运算符 T() :
builder = QueryBuilder(db.thing,
field_aliases={str(T(field.name)): field name for field in db.thing},
token_aliases={str(T(key):key) for key in QueryBuilder.token_ops})
您可以对以下令牌设置别名:
{
# boolean tokens
"not",
"and",
"or",
# field transformers
"upper",
"lower",
# unary search expressions
"is null",
"is not null",
"is true",
"is false",
# binary search expressions
"==",
"!=",
"<",
">",
"<=",
">=",
"contains",
"startswith", # notice "starts with" is an alias!
# search in list
"belongs",
}
查询生成器在 Grid 中使用。在 Grid 中,字段别名是小写的 field.label ,空格被下划线替换。
标记记录(Tagging records)
标记(Tags)功能可用于为数据库中的记录添加属性,或根据已附加的属性查找记录。
from py4web import DAL, Field
from pydal.tools.tags import Tags
db = DAL("sqlite:memory")
db.define_table("thing", Field("name"))
id1 = db.thing.insert(name="chair")
id2 = db.thing.insert(name="table")
properties = Tags(db.thing)
properties.add(id1, "color/red")
properties.add(id1, "style/modern")
properties.add(id2, "color/green")
properties.add(id2, "material/wood")
assert properties.get(id1) == ["color/red", "style/modern"]
assert properties.get(id2) == ["color/green", "material/wood"]
rows = db(properties.find(["style/modern"])).select()
assert rows.first().id == id1
rows = db(properties.find(["material/wood"])).select()
assert rows.first().id == id2
rows = db(properties.find(["color"])).select()
assert len(rows) == 2
Tags 具有层级结构。例如,执行 find([“color”]) 时,将返回 id1 和 id2 这两条记录,因为它们的 “标记” 中均包含 “color” 。
该功能在内部通过创建一个额外的表格实现,在本示例中,这个额外表格会是 db.thing_tags_default。出现 “default” 的原因是,在 Tags(table, tail=“default”) 这个构造函数中,上面的例子并未指定自定义的 “tail”(后缀)参数。
py4web 使用 Tags 作为一种灵活的机制来管理权限,我们稍后将在 使用 Tags 进行授权 中看到所有详细信息。
原始的 SQL 语句
executesql
DAL 允许您使用真正的 SQL 语句。
>>> db.executesql('SELECT * FROM person;')
[(1, u'Massimo'), (2, u'Massimo')]
这种情况下,DAL 不会再解析或者转换返回值,而且其格式依赖于特定的数据库驱动。通常不需要在 select 中使用这种用法,但在索引中更常见。
executesql 有五个可选的参数: placeholders 、 as_dict 、 fields 、 colnames 、 和 as_ordered_dict 。
placeholders 是一个可选的值的序列,用于替换 SQL 中的占位符;或者,如果数据库驱动程序支持,也可以是一个字典,其键与 SQL 中的命名占位符相匹配。
如果将 as_dict 设置为 True,数据库驱动程序返回的结果游标将被转换为一系列字典,这些字典以数据库字段名为键。 as_dict = True 时返回的结果与对普通 select 结果应用 as_list () 方法得到的结果相同:
[{'field1': val1_row1, 'field2': val2_row1}, {'field1': val1_row2, 'field2': val2_row2}]
as_ordered_dict 与 as_dict 非常相似,但前者确保结果字段的顺序(OrderedDict 的键的顺序)与数据库驱动程序返回它们的顺序一致:
[OrderedDict([('field1', val1_row1), ('field2', val2_row1)]),
OrderedDict([('field1', val1_row2), ('field2', val2_row2)])]
fields 参数是一个 DAL 字段(Field)对象的列表,这些对象与数据库返回的字段相匹配。这些字段对象应当是 DAL 对象上定义的一个或多个表(Table)对象的组成部分。 fields 列表除了可以包含字段对象,还可以包含一个或多个 DAL 表对象来补充或替代字段对象,也可以仅仅是一个单独的表(无需放在列表中)。在这种情况下,字段对象会从这些表中提取出来。
除了指定 fields 参数,还可以将 colnames 参数指定为一个字段名列表,字段名需采用 “tablename.fieldname” 的格式。同样,这些字段名所代表的表和字段应当是在 DAL 对象上定义过的。
也可以同时指定 fields 及其关联的 colnames。在这种情况下, fields 除了可以包含字段对象,还可以包含 DAL 表达式(Expression)对象。对于 fields 中的字段对象,其关联的 colnames 仍必须采用 “tablename.fieldname” 的格式;对于 fields 中的表达式对象,其关联的 colnames 可以是任意的标签。
需要注意的是,fields 或 colnames 所引用的 DAL 表对象可以是虚拟表(dummy tables),不必代表数据库中任何实际存在的表。另外,fields 或 colnames 的顺序必须与数据库返回的结果游标中的字段顺序一致。
_lastsql
无论 SQL 语句是使用 executesql 手动执行的,还是由 DAL 生成的,您都可以用 db._lastsql 返回真正的 SQL 语句代码。这对于调试目的很有用:
>>> rows = db().select(db.person.ALL)
>>> db._lastsql
SELECT person.id, person.name FROM person;
py4web 从不使用 “*” 运算符生成查询。py4web 的查询字段总是需要明确地指定。
查询的耗时
所有查询都由 py4web 自动计时。变量 db._timings 是一个元组列表。每个元组都包含传递给数据库驱动程序的原始 SQL 查询语句以及以秒为单位的执行时间。
索引
目前,DAL API 没有提供在表上创建索引的命令,但这可以使用 executesql 命令来完成。这是因为索引的存在会使迁移变得复杂,最好明确地处理它们。对于那些在查询中频繁使用的字段,可能需要为其创建索引。
这里是一个示例:
db = DAL('sqlite://storage.sqlite')
db.define_table('person', Field('name'))
db.executesql('CREATE INDEX IF NOT EXISTS myidx ON person (name);')
其他数据库方言具有非常相似的语法,但可能不支持可选的 “IF not EXISTS” 指令。
生成原始的 SQL 语句
有时您需要生成 SQL 语句,但不需要执行它。使用 py4web 很容易做到这一点,因为执行数据库读写操作的每个命令都有一个不执行的等效命令,并且只返回本应执行的 SQL 语句。这些命令的名称和语法与函数式命令相同,但它们以下划线开头:
下面是 _insert
>>> print(db.person._insert(name='Alex'))
INSERT INTO "person"("name") VALUES ('Alex');
下面是 _count
>>> print(db(db.person.name == 'Alex')._count())
SELECT COUNT(*) FROM "person" WHERE ("person"."name" = 'Alex');
下面是 _select
>>> print(db(db.person.name == 'Alex')._select())
SELECT "person"."id", "person"."name" FROM "person" WHERE ("person"."name" = 'Alex');
下面是 _delete
>>> print(db(db.person.name == 'Alex')._delete())
DELETE FROM "person" WHERE ("person"."name" = 'Alex');
最后,下面是 _update
>>> print(db(db.person.name == 'Alex')._update(name='Susan'))
UPDATE "person" SET "name"='Susan' WHERE ("person"."name" = 'Alex');
此外,无论是使用 executesql 手动执行还是DAL 生成的 SQL 语句,您始终可以使用
db._lastsql返回最近执行的 SQL 语句代码。
select 命令
有一个数据集合 s ,使用 select 命令能获取数据记录:
>>> rows = s.select()
这返回 pydal.objects.Rows 类的一个可迭代对象,里面的元素是 Row 对象。pydal.objects.Row 对象的行为像字典,但是它们的元素可以作为属性来访问。前者不同于后者,因为 Row 的元素的值是只读的。
Rows 对象允许循环查询( select )的结果,并打印每行中选定的字段值:
>>> for row in rows:
... print(row.id, row.name)
...
1 Alex
您可以在一个语句中完成所有步骤:
>>> for row in db(db.person.name == 'Alex').select():
... print(row.name)
...
Alex
select 命令可以接受参数。所有未命名的参数都被解释为要获取的字段的名称。例如,您可以显式获取字段 “id” 和字段 “name” 的值:
>>> for row in db().select(db.person.id, db.person.name):
... print(row.name)
...
Alex
Bob
Carl
表的 ALL 属性允许你指定全部字段:
>>> for row in db().select(db.person.ALL):
... print(row.id, row.name)
...
1 Alex
2 Bob
3 Carl
请注意,这里没有向 db 传递查询字符串。py4web 会自动识别:若你想获取 person 表的所有字段且无需额外信息,那么你需要的就是该表的所有记录。
等效的替代语法如下:
>>> for row in db(db.person).select():
... print(row.id, row.name)
...
1 Alex
2 Bob
3 Carl
而且 py4web 会理解:如果你想要 person 表的所有记录且无需额外信息,那么你需要的就是该表的所有字段。
给定一行
>>> row = rows[0]
您可以使用多个等效表达式提取其值:
>>> row.name
Alex
>>> row['name']
Alex
>>> row('person.name')
Alex
当要查询的是表达式而不是列时,后一种语法特别方便。稍后我们将展示这一点。
你也可以这样做
rows.compact = False
禁用以下形式
rows[i].name
相反地,启用了不那么紧凑的形式:
rows[i].person.name
是的,这是不常见,很少需要。
Row 对象也有两个重要地方法:
row.delete_record()
和
row.update_record(name="new value")
使用基于迭代器的查询以降低内存使用率
Python 的 “iterators” 是一种 “懒惰求值”。它们只为每次迭代 “提供” 那次用到的数据;而传统的 Python 循环,在循环之前就需要在内存中创建整个数据集。
查询的传统做法是:
for row in db(db.table).select():
...
但对于大量的数据行,使用基于迭代器的替代方案会大大降低内存使用率:
for row in db(db.table).iterselect():
...
测试表明,即使在具有大内存的机器上,这也快了大约 10%。
使用 represent 渲染行
您可能希望重写 select 返回的行,以利用字段 represents 设置中包含的格式信息。
rows = db(query).select()
repr_row = rows.render(0)
如果你不指定索引,你会得到一个生成器来迭代所有行:
for row in rows.render():
print(row.myfield)
也可以应用切片:
for row in rows[0:10].render():
print(row.myfield)
如果你只想通过选定字段的 “represent” 属性来转换它们,你可以在 “fields” 参数中列出它们:
repr_row = row.render(0, fields=[db.mytable.myfield])
注意,它返回原始行的转换副本,因此没有 update_record (无论如何你都不想要)或 delete_record 。
快捷语法
DAL 支持各种代码简化的快捷形式,特别地:
myrecord = db.mytable[id]
如果存在 id 字段与给定 id 的值相同的记录,则返回具那个记录。如果 id 在数据集中不存在,则返回 None 。上面地语句等效于:
myrecord = db(db.mytable.id == id).select().first()
能依据 id 删除记录:
del db.mytable[id]
而且这等效于:
db(db.mytable.id == id).delete()
如果给定 id 的值存在,则会删除相应记录。
注意:目前,如果激活了 versioning (版本控制),则删除记录的快捷语法不再起作用
您可以插入记录:
db.mytable[None] = dict(myfield='somevalue')
它等效于:
db.mytable.insert(myfield='somevalue')
它使用右侧字典指定的字段值来创建一条新记录。
注意:insert 的快捷语法以前的形式是 db.table[0] = ... 。这在 pyDAL 19.02 中已经更改为可以正常使用 0 作为 id 来表示要插入数据。
你可以更新记录:
db.mytable[id] = dict(myfield='somevalue')
它等效于:
db(db.mytable.id == id).update(myfield='somevalue')
它使用右侧字典指定的字段值来更新一条已存在的记录。
读取 Row
另一种方便的语法如下:
record = db.mytable(id)
record = db.mytable(db.mytable.id == id)
record = db.mytable(id, myfield='somevalue')
虽然看着与 db.mytable[id] 类似,但是上述语法更灵活、更安全。首先,它检查 id 是否为 int(或 str(id) 是否为 int ),如果不是,则返回 None (它从不引发异常)。它还允许指定记录必须满足的多个条件。如果不满足,它也会返回 None 。
递归的 select
设想还是前面的表 “person” 和一个引用 “person” 的新表 “thing” :
db.define_table('thing',
Field('name'),
Field('owner_id', 'reference person'))
表 “thing” 的一个简单查询:
things = db(db.thing).select()
它等效于:
things = db(db.thing._id != None).select()
其中 _id 是对表的主键的引用。通常是 db.thing._id 与 db.thing.id 相同,我们将在本书的大部分内容中假设这一点。
对于 “thing” 的每一行内容,不仅可以从表 “thing” 中获取字段,还可以从链接到的表(引用的表)中(递归地)获取:
for thing in things:
print(thing.name, thing.owner_id.name)
这里的 thing.owner_id.name ,需要为 things 中的每个 thing 执行一次数据库查询,因此效率较低。我们建议尽可能使用连接(join)操作,而非递归查询;不过,在访问单个记录时,这种方式既便捷又实用。
你也可以通过选择引用同一条 person 记录的 things 来反向执行:
person = db.person(id)
for thing in person.thing.select(orderby=db.thing.name):
print(person.name, 'owns', thing.name)
在这里,表达式 person.thing 是下面语法的快捷语法:
db(db.thing.owner_id == person.id)
即,引用当前 person 的一组 thing 集合。若引用表( thing )对被引用表( person )存在多个引用关系,此语法将无法正常使用。在这种情况下,需要更明确地使用完整的 Query。
orderby, groupby, limitby, distinct, having, orderby_on_limitby, join, left, cache
select 命令接受许多可选参数。
orderby
您能获取按 name 升序排序的记录:
>>> for row in db().select(db.person.ALL, orderby=db.person.name):
... print(row.name)
...
Alex
Bob
Carl
使用波浪号 “~”,您能获取按 name 降序排序的记录:
>>> for row in db().select(db.person.ALL, orderby=~db.person.name):
... print(row.name)
...
Carl
Bob
Alex
您可以让要获取的记录以随机顺序显示:
>>> for row in db().select(db.person.ALL, orderby='<random>'):
... print(row.name)
...
Carl
Alex
Bob
Google NoSQL 不支持使用
orderby='<random>'。为了解决这一限制,可以对查询后的行进行排序:
import random
rows = db(...).select().sort(lambda row: random.random())
你能对记录按多个字段排序,需要使用 “|” 把多个字段组合到一起。
>>> for row in db().select(db.person.name, orderby=db.person.name|db.person.id):
... print(row.name)
...
Alex
Bob
Carl
groupby, having
将 groupby 与 orderby 一块使用,您可以对指定字段具有相同值的记录进行分组(这是特定于后端数据库的,不适用于 Google NoSQL ):
>>> for row in db().select(db.person.ALL,
... orderby=db.person.name,
... groupby=db.person.name):
... print(row.name)
...
Alex
Bob
Carl
你可以将 having 与 groupby 结合使用,有条件地分组(只有那些满足 having 条件的人才会被分组)。
db(query1).select(db.person.ALL, groupby=db.person.name, having=query2)
注意,query1 筛选保留查询结果要显示的记录,而 query2 筛选哪些记录会被保留分组。
distinct
使用参数 distinct=True ,可以指定查询只保留不重复的记录。除了不需要排序之外,这与使用所有指定字段进行分组具有相同的效果。使用 distinct 时,重要的是,不应选择所有字段,也不要选择 “id” 字段,否则结果将返回所有记录始终。
这里是一个例子:
>>> for row in db().select(db.person.name, distinct=True):
... print(row.name)
...
Alex
Bob
Carl
注意, distinct 也可以是一个表达式,例如:
>>> for row in db().select(db.person.name, distinct=db.person.name):
... print(row.name)
...
Alex
Bob
Carl
limitby
使用 limitby=(min, max) ,能查询记录的一个子集,它从 offset=min 到 offset=max (不包括 max)。在下面的例子中,查询结果是从 0 开始的头两条记录:
>>> for row in db().select(db.person.ALL, limitby=(0, 2)):
... print(row.name)
...
Alex
Bob
orderby_on_limitby
请注意,DAL 默认在使用 limitby 时隐式添加 orderby 。这确保了相同的查询每次返回相同的结果,这对分页很重要。但这可能会导致性能问题。使用 orderby_on_limitby = False 更改此设置(默认为True)。
查询中的 “连接,左连接”
这些涉及管理 One to many relation 。它们分别在 Inner join 和 Left outer join 部分进行了描述。
cache, cacheable
一个提供更快查询的示例用法是:
rows = db(query).select(cache=(cache.get, 3600), cacheable=True)
查看 Caching selects ,了解权衡是什么。
逻辑操作
可以使用二进制 AND 运算符 “&” 组合查询条件:
>>> rows = db((db.person.name=='Alex') & (db.person.id > 3)).select()
>>> for row in rows: print row.id, row.name
>>> len(rows)
0
也可以使用二进制 OR 运算符 “|” :
>>> rows = db((db.person.name == 'Alex') | (db.person.id > 3)).select()
>>> for row in rows: print row.id, row.name
1 Alex
您可以通过否定查询来反转运算:
>>> rows = db((db.person.name != 'Alex') | (db.person.id > 3)).select()
>>> for row in rows: print row.id, row.name
2 Bob
3 Carl
或者用一元运算符 “~” 进行显式否定:
>>> rows = db(~(db.person.name == 'Alex') | (db.person.id > 3)).select()
>>> for row in rows: print row.id, row.name
2 Bob
3 Carl
由于 Python 在重载 “
and” 和 “or” 运算符方面的限制,这些运算符不能用于生成查询。必须改用二元运算符 “&” 和 “|” 。请注意,这些运算符(与 “and” 和 “or” 不同)的优先级高于比较运算符,因此上述示例中的 “额外” 的括号是强制性的。同样,一元运算符 “~” 的优先级高于比较运算符,因此~否定的内容也必须放在括号内。
也可以使用就地逻辑运算符构建查询:
>>> query = db.person.name != 'Alex'
>>> query &= db.person.id > 3
>>> query |= db.person.name == 'John'
count, isempty, delete, update
您可以对一个数据集中的记录计数:
>>> db(db.person.name != 'William').count()
3
请注意, count 接受一个可选的 distinct 参数,默认为 False,它的工作原理与 select 的相同参数非常相似。 count 还有一个 cache 参数,其工作原理与 select 方法的等效参数非常相似。
有时需要判断一个表是否为空。使用 isempty 会比 count 更有效:
>>> db(db.person).isempty()
False
可以这样删除一个数据集中的记录:
>>> db(db.person.id > 3).delete()
0
delete 方法返回已被删除的记录的数量。
通过传递与需要更新的字段对应的命名参数,你能更新一个数据集中的全部记录:
>>> db(db.person.id > 2).update(name='Ken')
1
update 方法返回已被更新的记录的数量。
表达式
为更新语句指定的值可以是表达式。例如,考虑这个模型:
db.define_table('person',
Field('name'),
Field('visits', 'integer', default=0))
db(db.person.name == 'Massimo').update(visits = db.person.visits + 1)
查询条件中也可以使用表达式:
db.define_table('person',
Field('name'),
Field('visits', 'integer', default=0),
Field('clicks', 'integer', default=0))
db(db.person.visits == db.person.clicks + 1).delete()
case
表达式可以包含 case 子句,例如:
>>> condition = db.person.name.startswith('B')
>>> yes_or_no = condition.case('Yes', 'No')
>>> for row in db().select(db.person.name, yes_or_no):
... print(row.person.name, row[yes_or_no]) # could be row(yes_or_no) too
...
Alex No
Bob Yes
Ken No
update_record
使用 update_record ,py4web 也允许更新内存中的单个记录:
>>> row = db(db.person.id == 2).select().first()
>>> row.update_record(name='Curt')
<Row {'id': 2, 'name': 'Curt'}>
update_record 不能和下面的混淆:
>>> row.update(name='Curt')
因为对于单独的 row , update 方法虽然像 update_record 一样更新 row 对象,但它不会更新数据库中的记录。
也能够先改变一个 row 对象(每次一个 row )的属性,再调用无参数的 update_record() 来保存变化。
>>> row = db(db.person.id > 2).select().first()
>>> row.name = 'Philip'
>>> row.update_record() # saves above change
<Row {'id': 3, 'name': 'Philip'}>
请注意,当
row对象包含具有update属性的字段时(例如Field('modified_on', update=datetime.datetime.utcnow)),应避免使用没有参数的row.update_record()。调用row.update_record()将保留row对象中的 所有 现有值,因此在这种情况下,任何具有update属性的字段都将无效。对于包含auth.signature的表,请特别注意这一点。
只有当表的 id 字段包含在查询结果中,并且 cacheable 未设置为 True``时, ``update_record 方法才可用。
从字典"中获取值来插入或更新记
一个常见的问题是需要在表中插入或更新记录,其中表的名称、要更新的字段和字段的值都存储在变量中。例如: tablename, fieldname 和 value。
使用下面的语法能够插入新记录:
db[tablename].insert(**{fieldname:value})
可以这样更新给定 id 的记录:
db(db[tablename]._id == id).update(**{fieldname:value})
请注意,我们使用了 table._id 而不是 table.id。这样,查询甚至适用于主键字段类型不是 “id” 的表。
commit 和 rollback
对于包含记录的 Rows 对象:
rows = db(query).select()
first_row = rows.first()
last_row = rows.last()
等效于:
first_row = rows[0] if len(rows) else None
last_row = rows[-1] if len(rows) else None
请注意, first() 和 last() 允许您获取查询中存在的第一条和最后一条记录,但这并不意味着这些记录将是第一条或最后一条插入的记录。如果你想在给定的表中读取第一条或最后一条插入的记录,别忘了使用 orderby=db.table_name.id 。如果你忘记了,你只会得到查询返回的第一条和最后一条,这些记录通常是由后端查询优化器确定的随机顺序。
as_dict 和 as_list
使用 as_dict() ,一个 Row 对象能够被序列化为一个常规的字典;使用 as_list() ,一个 Rows 对象能够被序列化为一个常规的字典列表。下面是示例:
rows = db(query).select()
rows_list = rows.as_list()
first_row_dict = rows.first().as_dict()
这些方法便于将 Rows 中的数据传递给通用视图或是存储到 sessions 中。(因为 Rows 对象包含对已打开的数据库连接的引用,所以它本身不能被直接序列化为字符串)
rows = db(query).select()
session.rows = rows # not allowed!
session.rows = rows.as_list() # allowed!
组合使用多个 rows
不同的 Rows 对象可以在 Python 中被组合使用。这里,我们假设:
>>> print(rows1)
person.name
Max
Tim
>>> print(rows2)
person.name
John
Tim
使用 + 把两个 rows 集合中的记录直接进行合并:
>>> rows3 = rows1 + rows2
>>> print(rows3)
person.name
Max
Tim
John
Tim
使用 | 把两个 rows 集合中的记录进行无重复的合并:
>>> rows3 = rows1 | rows2
>>> print(rows3)
person.name
Max
Tim
John
使用 & 获取两个 rows 集合中的相同的记录:
>>> rows3 = rows1 & rows2
>>> print(rows3)
person.name
Tim
find, exclude, sort
有时,您需要执行两次查询,其中一次包含前一次查询的子集。在这种情况下,再次访问数据库是没有意义的。 find、 exclude 和 sort 对象允许您操纵 Rows 对象并生成另一个对象,而无需再次访问数据库。更具体地说: - find 返回一组按条件筛选的新行,并保持原始行不变。 - exclude 返回一组按条件筛选的新行,并将其从原始行中删除。 - sort 返回一组按条件排序的新行,并保持原始行不变。
所有这些方法都接受一个参数,一个作用于每一行( row )的函数。
这里是用法的示例
>>> db.define_table('person', Field('name'))
<Table person (id, name)>
>>> db.person.insert(name='John')
1
>>> db.person.insert(name='Max')
2
>>> db.person.insert(name='Alex')
3
>>> rows = db(db.person).select()
>>> for row in rows.find(lambda row: row.name[0]=='M'):
... print(row.name)
...
Max
>>> len(rows)
3
>>> for row in rows.exclude(lambda row: row.name[0]=='M'):
... print(row.name)
...
Max
>>> len(rows)
2
>>> for row in rows.sort(lambda row: row.name):
... print(row.name)
...
Alex
John
它们可以组合在一起:
>>> rows = db(db.person).select()
>>> rows = rows.find(lambda row: 'x' in row.name).sort(lambda row: row.name)
>>> for row in rows:
... print(row.name)
...
Alex
Max
sort 接受一个可选的参数 reverse=True ,其含义显而易见。
find 方法有一个可选的 limitby 参数,其语法和功能与数据集 set 的 select 方法相同。
缓存查询
select 方法还接受一个 cache 参数,默认为 None。出于缓存目的,它应该设置为一个元组,其中第一个元素是带有签名 (key, callback, expiration) 的缓存函数(例如 cache.get 假设 cache 是 py4web 的缓存对象的实例),第二个元素是以秒为单位的过期时间。
在下面的示例中,您会看到一个控制器,它在之前定义的 db.log 表上缓存一个查询结果。实际从后端数据库获取数据的查询频率不超过每60秒一次,并将结果存储在内存中。如果对该控制器的下一次调用发生在距离上次数据库查询操作不到 60 秒的时间内,它只会从内存中获取之前的数据。
def cache_db_select():
logs = db().select(db.log.ALL, cache=(cache.get, 60))
return dict(logs=logs)
select 方法有一个可选的参数 cacheable ,通常设置为 False。当设置为 cacheable=True 时,生成的 Rows 是可序列化的,但这种情况下的 Rows 没有 update_record 和 delete_record 方法。
如果你不需要这些方法,可以通过设置 cacheable 属性来大大加快查询速度
rows = db(query).select(cacheable=True)
当 cache 参数已设置但当 cacheable=False (默认值)时,就仅缓存数据库查询结果,而非实际的 Rows 对象。当 cache 参数与 cacheable=True 结合使用时,整个 Rows 对象会被缓存,从而实现更快的缓存速度:
rows = db(query).select(cache=(cache.get, 3600), cacheable=True)
计算字段和虚拟字段
计算结果字段
DAL 字段可能具有 compute 属性。这必须是一个函数(或 lambda ),它接受一个 Row 对象并为字段返回计算后的值。当有新的修改记录时,包括插入和更新,如果未提供字段的值,py4web 将尝试使用 compute 函数从其他字段值进行计算。以下是一个示例:
>>> db.define_table('item',
... Field('unit_price', 'double'),
... Field('quantity', 'integer'),
... Field('total_price',
... compute=lambda r: r['unit_price'] * r['quantity']))
<Table item (id, unit_price, quantity, total_price)>
>>> rid = db.item.insert(unit_price=1.99, quantity=5)
>>> db.item[rid]
<Row {'total_price': '9.95', 'unit_price': 1.99, 'id': 1L, 'quantity': 5}>
请注意,计算后的值存储在数据库中,在检索时不会再计算,就像下面描述的虚拟字段的情况一样。计算结果字段的两个典型应用是:
在 wiki 应用程序中,将经过处理的输入文本存储为 HTML ,以避免在每个请求时在对其进行重新处理
在搜索场景下,需为某个字段计算标准化的值,以供搜索功能使用。
计算结果字段按照在表定义中定义的顺序进行计算。计算结果字段可以使用在它之前定义的计算结果字段的值。
虚拟字段
虚拟字段也是计算结果字段(如前一小节所述),但不同之处是,它们是虚拟的,因为它们不存储在数据库中,所以每次从数据库中提取记录时,它们都会被重新计算。它们可用于简化用户的代码,而无需使用额外的存储空间,但不能用于搜索。
新式虚拟字段(实验)
py4web 提供了一种新的、更简单的方法来定义虚拟字段和惰性虚拟字段。本节标记为实验性,因为最终的 API 可能仍会与此处描述的有所不同。
在这里,我们将考虑与上一小节中相同的示例。我们特别考虑以下模型:
db.define_table('item',
Field('unit_price', 'double'),
Field('quantity', 'integer'))
可以像这样定义一个名为 total_price 的虚拟字段:
db.item.total_price = Field.Virtual(lambda row: row.item.unit_price * row.item.quantity)
即通过简单地将一个新字段 total_price 定义为 Field.Virtual。虚拟构造函数的唯一参数是一个函数,它接受一个 row 对象并返回计算后的值。
当查询记录时,会自动为所有记录计算如上定义的虚拟字段:
for row in db(db.item).select():
print(row.total_price)
还可以定义方法字段,这些字段在调用时按需计算。例如:
db.item.discounted_total = \
Field.Method(lambda row, discount=0.0:
row.item.unit_price * row.item.quantity * (100.0 - discount / 100))
在这种情况下,row.discounted_total 不是一个值,而是一个函数。该函数接受与传递给 Method 构造函数的函数相同的参数,除了 row 是隐式的(可以将其视为对象的 self )。
上面示例中的懒惰字段允许计算每个 item 的总价:
for row in db(db.item).select(): print(row.discounted_total())
它还允许通过一个可选的 discount 百分比(比如 15% ):
for row in db(db.item).select(): print(row.discounted_total(15))
也可以在表的定义中定义虚拟字段和方法字段。
db.define_table('item',
Field('unit_price', 'double'),
Field('quantity', 'integer'),
Field.Virtual('total_price', lambda row: ...),
Field.Method('discounted_total', lambda row, discount=0.0: ...))
请记住,虚拟字段没有常规字段的属性( length、default、required 等)。它们不在
db.table.fields的列表里面。
旧式虚拟字段
为了定义一个或多个虚拟字段,您还可以定义一个容器类,实例化它并将其链接到一个表或一个查询。例如,考虑下表:
db.define_table('item',
Field('unit_price', 'double'),
Field('quantity', 'integer'))
可以像这样定义一个名为 total_price 的虚拟字段:
class MyVirtualFields:
def total_price(self):
return self.item.unit_price * self.item.quantity
db.item.virtualfields.append(MyVirtualFields())
请注意,类中接受单个参数(self)的每个方法都是一个新的虚字段。 self 指的是查询中的每个 row 。字段值由 self.item.unit_price 中的完整路径引用。通过将类的实例附加到表的 virtualfields 属性,将表链接到虚拟字段。
虚拟字段也可以访问递归字段,如
db.define_table('item',
Field('unit_price', 'double'))
db.define_table('order_item',
Field('item', 'reference item'),
Field('quantity', 'integer'))
class MyVirtualFields:
def total_price(self):
return self.order_item.item.unit_price * self.order_item.quantity
db.order_item.virtualfields.append(MyVirtualFields())
请注意,递归字段访问的语句 self.order_item.item.unit_price 中, self 代表循环中的当前记录。
它们也可以对 JOIN 的结果进行操作。
rows = db(db.order_item.item == db.item.id).select()
class MyVirtualFields:
def total_price(self):
return self.item.unit_price * self.order_item.quantity
rows.setvirtualfields(order_item=MyVirtualFields())
for row in rows:
print(row.order_item.total_price)
注意在这种情况下,语法有何不同。虚拟字段同时访问 self.item.unit_price 和 self.order_item.quantity ,它们都属于连接查询( join )。虚拟字段通过 rows 对象的 setvirtualfields 方法附加到表的 rows 上。该方法接受任意数量的命名参数,可用于设置多个虚拟字段,这些字段可以定义在多个类中,并附加到多个表上:
class MyVirtualFields1:
def discounted_unit_price(self):
return self.item.unit_price * 0.90
class MyVirtualFields2:
def total_price(self):
return self.item.unit_price * self.order_item.quantity
def discounted_total_price(self):
return self.item.discounted_unit_price * self.order_item.quantity
rows.setvirtualfields(item=MyVirtualFields1(),
order_item=MyVirtualFields2())
for row in rows:
print(row.order_item.discounted_total_price)
虚拟字段可以是惰性的;它们所需要做的只是返回一个函数,并通过调用该函数来访问它:
db.define_table('item',
Field('unit_price', 'double'),
Field('quantity', 'integer'))
class MyVirtualFields:
def lazy_total_price(self):
def lazy(self=self):
return self.item.unit_price * self.item.quantity
return lazy
db.item.virtualfields.append(MyVirtualFields())
for item in db(db.item).select():
print(item.lazy_total_price())
或者使用 lambda 函数会更简短:
class MyVirtualFields:
def lazy_total_price(self):
return lambda self=self: self.item.unit_price * self.item.quantity
连接和关系
一对多关系
为了演示如何使用数据访问层(DAL)实现一对多关系,请定义另一个名为 “thing” 的表,该表引用我们在这里重新定义的 “person” 表:
>>> db.define_table('person',
... Field('name'))
<Table person (id, name)>
>>> db.person.insert(name='Alex')
1
>>> db.person.insert(name='Bob')
2
>>> db.person.insert(name='Carl')
3
>>> db.define_table('thing',
... Field('name'),
... Field('owner_id', 'reference person'))
<Table thing (id, name, owner_id)>
表 “thing” 有两个字段,即物品的名称和物品的所有者。“owner_id” 字段是一个引用字段,它的作用是通过 ID 引用另一个表。引用类型可以通过两种等效的方式指定,即:Field('owner_id', 'reference person') 或:Field('owner_id', db.person)。
后者总是会被转换为前者。它们是等效的,但在惰性表、自引用或其他类型的循环引用情况下,就只能使用前者。
现在,插入三件物品,其中两件属于 Alex ,一件属于 Bob:
>>> db.thing.insert(name='Boat', owner_id=1)
1
>>> db.thing.insert(name='Chair', owner_id=1)
2
>>> db.thing.insert(name='Shoes', owner_id=2)
3
您可以像对其他表一样对它进行查询:
>>> for row in db(db.thing.owner_id == 1).select():
... print(row.name)
...
Boat
Chair
因为 thing 有一个指向 person 的引用,一个 person 可以拥有许多 things,所以 person 表的记录现在获得了一个新的属性 thing,它是一个集合,用于定义某个 person 的所拥有的 things。这允许我们遍历所有的 person 并轻松获取他们的 things:
>>> for person in db().select(db.person.ALL):
... print(person.name)
... for thing in person.thing.select():
... print(' ', thing.name)
...
Alex
Boat
Chair
Bob
Shoes
Carl
内连接
实现类似结果的另一种方式是使用连接,特别是 INNER JOIN。 当查询需要将两个或多个表关联时,py4web 会自动且透明地执行连接,如以下示例所示:
>>> rows = db(db.person.id == db.thing.owner_id).select()
>>> for row in rows:
... print(row.person.name, 'has', row.thing.name)
...
Alex has Boat
Alex has Chair
Bob has Shoes
请注意,py4web 执行了一个连接操作,因此现在每行包含两个记录,每个表各一个,并且它们已连接在一起。由于这两个记录可能具有字段名冲突,在从行中提取字段值时需要指定表。这意味着虽然之前你可以这样做:
row.name
这是指一个 person 的名字还是一个 thing 的,非常显而易见,在连接(join)的结果中,你必须更明确地说明,并且要这样说:
row.person.name
或:
row.thing.name
这里由 INNER JOIN 的一种替代语法:
>>> rows = db(db.person).select(join=db.thing.on(db.person.id == db.thing.owner_id))
>>> for row in rows:
... print(row.person.name, 'has', row.thing.name)
...
Alex has Boat
Alex has Chair
Bob has Shoes
虽然输出相同,但两种情况下生成的 SQL 可能不同。后一种语法在同一表被连接两次并使用别名时可以消除可能的歧义:
db.define_table('thing',
Field('name'),
Field('owner_id1', 'reference person'),
Field('owner_id2', 'reference person'))
rows = db(db.person).select(
join=[db.person.with_alias('owner_id1').on(db.person.id == db.thing.owner_id1),
db.person.with_alias('owner_id2').on(db.person.id == db.thing.owner_id2)])
join 的值可以是要连接的 db.table.on(...) 列表。
左外连接
注意 Carl 没有出现在上面的列表中,因为他没有任何 things。如果你打算查询人员(无论他们是否有事物)及其事物(如果有的话),那么你需要执行 LEFT OUTER JOIN(左外连接)。这是通过在 select 中使用参数 “left” 来完成的。这里是一个示例:
>>> rows = db().select(db.person.ALL, db.thing.ALL,
... left=db.thing.on(db.person.id == db.thing.owner_id))
>>> for row in rows:
... print(row.person.name, 'has', row.thing.name)
...
Alex has Boat
Alex has Chair
Bob has Shoes
Carl has None
上面的:
left = db.thing.on(...)
执行左连接查询。这里 db.thing.on 的参数是进行连接所需的条件(与上面内连接中使用的相同)。在进行左连接时,需要明确选择哪些字段。
可以通过将 db.mytable.on(...) 的列表或元组传递给 left 参数来组合多个左连接。
分组与计数
在进行连接时,有时你希望根据某些条件对记录进行分组并进行计数。例如,统计每个人拥有的物品数量。py4web 也支持这种操作。首先,你需要一个计数运算符。其次,你需要通过 “拥有” 将 person 表与 thing 表进行连接。第三,你希望选择所有行(person + thing),按 person 分组,并在分组时进行计数:
>>> count = db.person.id.count()
>>> for row in db(db.person.id == db.thing.owner_id
... ).select(db.person.name, count, groupby=db.person.name):
... print(row.person.name, row[count])
...
Alex 2
Bob 1
请注意,count 运算符(内置的)是作为一个字段使用的。这里唯一的问题是如何获取信息。每一行显然包含一个人和计数,但计数既不是该人的字段,也不是一个表。那么它应该放在哪里呢?它会放入表示记录的存储对象中,其键等于查询表达式本身。
Field 对象的 count 方法有一个可选的 distinct 参数。当设置为 True 时,它指定只计算该字段的不同值。
多对多关系
在前面的例子中,我们允许一个 thing 有一个所有者,但一个 person 可以拥有多个 things。如果 boat 同时属于 Alex 和 Curt 呢?这是多对多的关系,它需要通过一个中间表来实现,该表通过所有关系将人和物品连接起来。
下面是实现方法:
>>> db.define_table('person',
... Field('name'))
<Table person (id, name)>
>>> db.person.bulk_insert([dict(name='Alex'), dict(name='Bob'), dict(name='Carl')])
[1, 2, 3]
>>> db.define_table('thing',
... Field('name'))
<Table thing (id, name)>
>>> db.thing.bulk_insert([dict(name='Boat'), dict(name='Chair'), dict(name='Shoes')])
[1, 2, 3]
>>> db.define_table('ownership',
... Field('person', 'reference person'),
... Field('thing', 'reference thing'))
<Table ownership (id, person, thing)>
现有的所有关系现在可以重写为:
>>> db.ownership.insert(person=1, thing=1) # Alex owns Boat
1
>>> db.ownership.insert(person=1, thing=2) # Alex owns Chair
2
>>> db.ownership.insert(person=2, thing=3) # Bob owns Shoes
3
现在你可以添加 Curt 也拥有 Boat 的新关系:
>>> db.ownership.insert(person=3, thing=1) # Curt owns Boat too
4
你现在在两个表之间有一个第三方关系,因此定义一个新的集合来执行操作可能会更方便:
>>> persons_and_things = db((db.person.id == db.ownership.person) &
... (db.thing.id == db.ownership.thing))
现在很容易从新的集合中查询全部的 persons 及他们拥有的物品:
>>> for row in persons_and_things.select():
... print(row.person.name, 'has', row.thing.name)
...
Alex has Boat
Alex has Chair
Bob has Shoes
Curt has Boat
类似地,你能查询 Alex 拥有的全部 things:
>>> for row in persons_and_things(db.person.name == 'Alex').select():
... print(row.thing.name)
...
Boat
Chair
和 boat 的全部拥有者:
>>> for row in persons_and_things(db.thing.name == 'Boat').select():
... print(row.person.name)
...
Alex
Curt
比多对多关系更轻量的做法是标签化(tagging),请参见 使用 Tags 进行授权 一章。即使在不支持 JOIN 的数据库后端(如 Google App Engine 的 NoSQL)上,标签化(tagging)也能正常工作。
自引用与别名
可以定义包含自引用字段的表,例如:
db.define_table('person',
Field('name'),
Field('father_id', 'reference person'),
Field('mother_id', 'reference person'))
注意,在此情况下,如果使用表对象作为字段类型就会失败,因为它在表定义之前就使用了还没定义完整的自身,例如:
db.define_table('person',
Field('name'),
Field('father_id', db.person), # wrong!
Field('mother_id', db['person'])) # wrong!
一般来说, db.tablename 和 'reference tablename' 是等效的字段类型,但后者是唯一允许自引用的字段类型。
当一个表有自引用并且您必须进行连接接(join)查询时,例如选择一个人及其父亲,您需要一个表的别名。在 SQL 中,别名是一个临时备用的名称,可用于将表/列引用到查询(或其他 SQL 语句)中。
使用 py4web,您可以使用 with_alias 方法为表创建别名。这也适用于表达式,这意味着也适用于字段,因为 Field 是从 Expression 派生出来的。
这里是一个例子:
>>> fid, mid = db.person.bulk_insert([dict(name='Massimo'), dict(name='Claudia')])
>>> db.person.insert(name='Marco', father_id=fid, mother_id=mid)
3
>>> Father = db.person.with_alias('father')
>>> Mother = db.person.with_alias('mother')
>>> type(Father)
<class 'pydal.objects.Table'>
>>> str(Father)
'person AS father'
>>> rows = db().select(db.person.name, Father.name, Mother.name,
... left=(Father.on(Father.id == db.person.father_id),
... Mother.on(Mother.id == db.person.mother_id)))
>>> for row in rows:
... print(row.person.name, row.father.name, row.mother.name)
...
Massimo None None
Claudia None None
Marco Massimo Claudia
请注意,我们选择做了区分:-“father_id”:表 “person” 中使用的字段名;-“father”:我们想为被上述字段引用的表使用的别名;这被传送到数据库;-“Father”:py4web 使用的变量,用来引用别名对应的对象。
区别是微妙的,对这三个词使用相同的名字并没有错:
>>> db.define_table('person',
... Field('name'),
... Field('father', 'reference person'),
... Field('mother', 'reference person'))
<Table person (id, name, father, mother)>
>>> fid, mid = db.person.bulk_insert([dict(name='Massimo'), dict(name='Claudia')])
>>> db.person.insert(name='Marco', father=fid, mother=mid)
3
>>> father = db.person.with_alias('father')
>>> mother = db.person.with_alias('mother')
>>> rows = db().select(db.person.name, father.name, mother.name,
... left=(father.on(father.id==db.person.father),
... mother.on(mother.id==db.person.mother)))
>>> for row in rows:
... print(row.person.name, row.father.name, row.mother.name)
...
Massimo None None
Claudia None None
Marco Massimo Claudia
但为了构建正确的查询,明确地区分很重要。
其他运算符
py4web 还有其他运算符,它们提供了一个 API 来访问等价的 SQL 运算符。让我们定义另一个表 “log” 来存储安全事件、事件时间和严重性,其中严重性是一个整数。
>>> db.define_table('log', Field('event'),
... Field('event_time', 'datetime'),
... Field('severity', 'integer'))
<Table log (id, event, event_time, severity)>
如前所述,插入一些事件, “port scan” 、“xss injection” 和 “unauthorized login”。为了示例,您可以记录具有相同 event_time 但严重程度不同(分别为 1、2 和 3 )的事件。
>>> import datetime
>>> now = datetime.datetime.now()
>>> db.log.insert(event='port scan', event_time=now, severity=1)
1
>>> db.log.insert(event='xss injection', event_time=now, severity=2)
2
>>> db.log.insert(event='unauthorized login', event_time=now, severity=3)
3
like, ilike, regexp, startswith, endswith, contains, upper, lower
字段有一个 like 运算符,可用于匹配字符串:
>>> for row in db(db.log.event.like('port%')).select():
... print(row.event)
...
port scan
这里的 “port%” 表示以 “port” 开头的字符串。 “ % ” 是一个通配符,代表 “任意地字符序列” 。
like 运算符映射到 ANSI-SQL 中的 LIKE 关键字。在大多数数据库中,LIKE 是区分大小写的,其行为取决于数据库自身的规则。因此,like 方法区分大小写,但可以通过以下方式使其不区分大小写:
db.mytable.myfield.like('value', case_sensitive=False)
其作用和使用 ilike 相同:
db.mytable.myfield.ilike('value')
py4web 也提供了一些便捷形式:
db.mytable.myfield.startswith('value')
db.mytable.myfield.endswith('value')
db.mytable.myfield.contains('value')
它们大致相当于:
db.mytable.myfield.like('value%')
db.mytable.myfield.like('%value')
db.mytable.myfield.like('%value%')
请记住, contains 对 list:<type> 字段有特殊含义,如 list:<type> 和 contains 中所述。
也能把一些值组成的列表传递给 contains 方法,同时还有一个可选的 boolean 参数 all 决定着搜索的字段要包含列表中的每个值:
db.mytable.myfield.contains(['value1', 'value2'], all=True)
或者包含列表中的任意一个值:
db.mytable.myfield.contains(['value1', 'value2'], all=False)
还有一个 regexp 方法,其工作方式与 like 方法类似,但允许查找表达式使用正则表达式语法。它只支持 MySQL、Oracle、PostgreSQL、SQLite 和 MongoDB (支持程度不同)。
upper 和 lower 方法允许您将字段的值转换为大写或小写,您还可以将它们与 like 运算符组合在一起:
>>> for row in db(db.log.event.upper().like('PORT%')).select():
... print(row.event)
...
port scan
year, month, day, hour, minutes, seconds
date 和 datetime 类型的字段有 day 、 month 和 year 方法。datetime 和 time 类型的字段有 hour 、 minutes 、 seconds 方法。这里是一个例子:
>>> for row in db(db.log.event_time.year() > 2018).select():
... print(row.event)
...
port scan
xss injection
unauthorized login
belongs
belongs 方法实现了 SQL 语法中的 IN 的操作,当字段的值在某个指定的 set(list 或 tuples)中时,它返回 true 。
>>> for row in db(db.log.severity.belongs((1, 2))).select():
... print(row.event)
...
port scan
xss injection
DAL 还允许嵌套查询作为 belongs 运算符的参数。唯一需要注意的是,嵌套的查询必须使用 _select ,而不是 select ,并且只能明确地指定一个要查询的字段,即定义集合的字段。
>>> bad_days = db(db.log.severity == 3)._select(db.log.event_time)
>>> for row in db(db.log.event_time.belongs(bad_days)).select():
... print(row.severity, row.event)
...
1 port scan
2 xss injection
3 unauthorized login
在需要嵌套查询并且查找字段类型是引用的情况下,我们也可以使用 query 作为参数。例如:
db.define_table('person', Field('name'))
db.define_table('thing',
Field('name'),
Field('owner_id', 'reference person'))
db(db.thing.owner_id.belongs(db.person.name == 'Jonathan')).select()
在这个例子中,嵌套地查询只需要被 db.thing.owner_id 引用的字段,因此我们不再需要额外多余的 _select 。
一个嵌套查询也能够作为 insert/update 的参数值使用,但是在这种情况下的语法有些不同:
lazy = db(db.person.name == 'Jonathan').nested_select(db.person.id)
db(db.thing.id == 1).update(owner_id = lazy)
在这种情况下, lazy 是一个嵌套的表达式,它计算 “Jonathan” 这个人对应的 id 。这两行会生成一个单一的 SQL 查询。
sum, avg, min, max and len
在前面,您使用过 count 运算符对记录进行计数。同样,您可以使用 sum 运算符将一组记录中特定字段的值相加(求和)。与计数的情况一样,通过存储对象检索 sum 的结果:
>>> sum = db.log.severity.sum()
>>> print(db().select(sum).first()[sum])
6
您也能使用 avg 、 min 和 max 分别对查询后的记录计算平均值、最小值和最大值。例如:
>>> max = db.log.severity.max()
>>> print(db().select(max).first()[max])
3
len 计算字段值的长度。它一般被用于 string 或 text 类型的字段。但是在后端数据库支持的情况下,它可能也会用于其他类型 (boolean, integer 等)。
>>> for row in db(db.log.event.len() > 13).select():
... print(row.event)
...
unauthorized login
表达式能被组合而形成更复杂的表达式。例如,这里我们计算的是日志中事件字符串长度加 1 的总和:
>>> exp = (db.log.event.len() + 1).sum()
>>> db().select(exp).first()[exp]
43
子字符串
可以构建一个表达式来引用子字符串。例如,我们可以将名称以相同的三个字符开头的事物分组,并从每组中只选择一个:
db(db.thing).select(distinct = db.thing.name[:3])
coalesce 和 coalesce_zero
有时,您需要从数据库中提取一个值,但如果记录的值已被设置为 NULL ,则还需要一个默认值。在 SQL 中,有一个函数 COALESCE 用于此。py4web 有一个等效的 coalesce 方法:
>>> db.define_table('sysuser', Field('username'), Field('fullname'))
<Table sysuser (id, username, fullname)>
>>> db.sysuser.insert(username='max', fullname='Max Power')
1
>>> db.sysuser.insert(username='tim', fullname=None)
2
>>> coa = db.sysuser.fullname.coalesce(db.sysuser.username)
>>> for row in db().select(coa):
... print(row[coa])
...
Max Power
tim
其他时候,你需要计算一个数学表达式,但有些字段的值默认被设置为 None ,而实际它应该为零。 coalesce_zero 在查询中起到了弥补作用,它将默认的 None 换为零:
>>> db.define_table('sysuser', Field('username'), Field('points'))
<Table sysuser (id, username, points)>
>>> db.sysuser.insert(username='max', points=10)
1
>>> db.sysuser.insert(username='tim', points=None)
2
>>> exp = db.sysuser.points.coalesce_zero().sum()
>>> db().select(exp).first()[exp]
10
>>> type(exp)
<class 'pydal.objects.Expression'>
>>> print(exp)
SUM(COALESCE("sysuser"."points",'0'))
导出和导入数据
CSV(一次一个表)
当 Rows 对象被转换为字符串时,它会自动以 CSV 格式序列化:
>>> rows = db(db.person.id == db.thing.owner_id).select()
>>> print(rows)
person.id,person.name,thing.id,thing.name,thing.owner_id
1,Alex,1,Boat,1
1,Alex,2,Chair,1
2,Bob,3,Shoes,2
您可以将单个表序列化为 CSV 格式,并将其存储在文件 “test.CSV” 中:
with open('test.csv', 'wb') as dumpfile:
dumpfile.write(str(db(db.person).select()))
将 Rows 对象转换为字符串时会生成某种编码的二进制字符串,最好明确指定所使用的编码:
with open('test.csv', 'w', encoding='utf-8', newline='') as dumpfile:
dumpfile.write(str(db(db.person).select()))
这等效于
rows = db(db.person).select()
with open('test.csv', 'wb') as dumpfile:
rows.export_to_csv_file(dumpfile)
您可以读回 CSV 文件:
with open('test.csv', 'rb') as dumpfile:
db.person.import_from_csv_file(dumpfile)
再次说明,你应该明确地指定导出文件的编码
rows = db(db.person).select()
with open('test.csv', 'w', encoding='utf-8', newline='') as dumpfile:
rows.export_to_csv_file(dumpfile)
和导入文件的编码:
with open('test.csv', 'r', encoding='utf-8', newline='') as dumpfile:
db.person.import_from_csv_file(dumpfile)
导入时,py4web 会在 CSV 第一行标头中查找字段名称。在这个例子中,它找到了两列:“person.id” 和 “person.name” 。它忽略了 “person.” 前缀,也忽略了 “id” 字段。然后,所有记录都会被添加并分配新的 id 。
CSV(一次所有表)
在 py4web 中,您可以使用两个命令备份/还原整个数据库:
要导出:
with open('somefile.csv', 'w', encoding='utf-8', newline='') as dumpfile:
db.export_to_csv_file(dumpfile)
要导入:
with open('somefile.csv', 'r', encoding='utf-8', newline='') as dumpfile:
db.import_from_csv_file(dumpfile)
即使导入数据库与导出数据库的类型不同,也可以使用此机制。
数据以 csv 文件的形式存储在 “somefile.csv” 中,其中每个表都以一行表示表名,另一行表示字段名:
TABLE tablename
field1,field2,field3,...
两个表之间用 \r\n\r\n 分隔开(那是两个空行)。整个文件以下面的行结束:
END
如果上传的文件未存储在数据库中,则导出文件不包括那些上传的文件。存储在文件系统上的上传文件必须单独转储,在大多数情况下, 将 “uploads” 文件夹压缩成 zip 文件即可满足需求。
导入时,如果数据不为空,新记录将被添加到数据库中。一般来说,新导入的记录与原始(已保存)记录的记录 id 不同,但 py4web 会恢复引用,即使原记录的 id 值发生变化,引用关系也不会断裂。
如果一个表包含一个名为 uuid 的字段,则该字段将用于识别重复项。此外,如果要导入的记录与已有记录具有相同的 uuid ",则已有的记录将被更新。
CSV 与远程数据库同步
再次考虑以下模型:
db.define_table('person',
Field('name'))
db.define_table('thing',
Field('name'),
Field('owner_id', 'reference person'))
# usage example
if db(db.person).isempty():
nid = db.person.insert(name='Massimo')
db.thing.insert(name='Chair', owner_id=nid)
每条记录都由一个标识符标识 id ,并由该 id 引用。如果您有两个由不同 py4web 安装使用的数据库副本,则 id 仅在每个数据库内是唯一的,而不是在数据库之间。当合并来自不同数据库的记录时,这是一个问题。
为了使记录在不同数据库中也是唯一的,它们必须:- 具有唯一的 id(UUID);- 具有最后修改时间来跟踪多个副本中的最新的那个;- 引用 UUID 代替一般的 id。
这可以通过将上述模型更改为:
import datetime
import uuid
now = datetime.datetime.utcnow
db.define_table('person',
Field('uuid', length=64),
Field('modified_on', 'datetime', default=now, update=now),
Field('name'))
db.define_table('thing',
Field('uuid', length=64),
Field('modified_on', 'datetime', default=now, update=now),
Field('name'),
Field('owner_id', length=64))
db.person.uuid.default = db.thing.uuid.default = lambda:str(uuid.uuid4())
db.thing.owner_id.requires = IS_IN_DB(db, 'person.uuid', '%(name)s')
# usage example
if db(db.person).isempty():
nid = str(uuid.uuid4())
db.person.insert(uuid=nid, name='Massimo')
db.thing.insert(name='Chair', owner_id=nid)
请注意,在上面的表定义中,两个
uuid字段的默认值被设置为一个 lambda 函数,该函数返回一个 uuid(转换为字符串)。插入的每条记录调用一次 lambda 函数,确保每条记录都有一个唯一的 UUID,即使在单个事务中插入了多条记录。
创建一个控制器 action 以导出数据库:
from py4web import response
def export():
s = StringIO.StringIO()
db.export_to_csv_file(s)
response.set_header('Content-Type', 'text/csv')
return s.getvalue()
创建另一个控制器 action 以导入其他数据库中已保存记录的副本并同步记录:
from yatl.helpers import FORM, INPUT
def import_and_sync():
form = FORM(INPUT(_type='file', _name='data'), INPUT(_type='submit'))
if form.process().accepted:
db.import_from_csv_file(form.vars.data.file, unique=False)
# for every table
for tablename in db.tables:
table = db[tablename]
# for every uuid, delete all but the latest
items = db(table).select(table.id, table.uuid,
orderby=~table.modified_on,
groupby=table.uuid)
for item in items:
db((table.uuid == item.uuid) & (table.id != item.id)).delete()
return dict(form=form)
您可以选择手动创建索引,以加快按 uuid 搜索的速度。
或者,您可以使用 XML-RPC 导出/导入文件。
如果记录引用了上传的文件,您还需要导出/导入上传文件夹的内容。请注意,其中的文件已经用 UUID 标记,因此您不必担心命名冲突和引用。
HTML 和 XML (一次一个表)
Rows 对象还有一个 xml 方法(类似 heplers),它可以将 Rows 对象序列化为XML/HTML:
>>> rows = db(db.person.id == db.thing.owner_id).select()
>>> print(rows.xml())
<table>
<thead>
<tr><th>person.id</th><th>person.name</th>
<th>thing.id</th><th>thing.name</th>
<th>thing.owner_id</th>
</tr>
</thead>
<tbody>
<tr class="w2p_odd odd">
<td>1</td><td>Alex</td>
<td>1</td><td>Boat</td>
<td>1</td>
</tr>
<tr class="w2p_even even">
<td>1</td><td>Alex</td>
<td>2</td><td>Chair</td>
<td>1</td>
</tr>
<tr class="w2p_odd odd">
<td>2</td><td>Bob</td>
<td>3</td>
<td>Shoes</td>
<td>2</td>
</tr>
</tbody>
</table>
如果你需要使用自定义标签以任何其他 XML 格式序列化 Rows,你可以使用我们稍后将看到的通用 TAG XML helper 和函数调用中允许的 Python 语法 *<iterable> 轻松完成:
>>> rows = db(db.person).select()
>>> print(TAG.result(*[TAG.row(*[TAG.field(r[f], _name=f) for f in db.person.fields]) for r in rows]))
<result>
<row><field name="id">1</field><field name="name">Alex</field></row>
<row><field name="id">2</field><field name="name">Bob</field></row>
<row><field name="id">3</field><field name="name">Carl</field></row>
</result>
警告
不要将这里使用的 TAG XML helper (请参阅 TAG 一章)与 Tags 方法混淆,后者将在 使用 Tags 进行授权 一章中详细解释。
Data representation
Rows.export_to_csv_file 方法接受一个名为 represent 的关键字参数。当设置为 True 时,它将在导出数据时使用列的 represent 函数,而不是原始数据。
该函数还接受一个名为 colnames 的关键字参数,该参数应包含要导出的列名列表。它默认为所有列。
export_to_csv_file 和 import_from_csv_file 都接受关键字参数,这些参数告诉 csv 解析器保存/加载文件的格式:- delimiter :分隔值的分隔符(默认为“,”);- quotechar :用于引用字符串值的字符(默认为双引号);- quoting :添加引号的规则(默认为 csv.QUOTE_MINIMAL)
以下是一些用法示例:
import csv
rows = db(query).select()
with open('/tmp/test.txt', 'wb') as oufile:
rows.export_to_csv_file(oufile,
delimiter='|',
quotechar='"',
quoting=csv.QUOTE_NONNUMERIC)
呈现结果类似于
"hello"|35|"this is the text description"|"2013-03-03"
有关更多信息,请参阅 Python 官方文档。
高级功能
list:<type> 和 contains
py4web 提供以下特殊字段类型:
list:string
list:integer
list:reference <table>
它们可以分别包含字符串列表、整数列表和引用列表。
在 Google App Engine NoSQL list:string 被映射到 StringListProperty ,另外两个被映射到 ListProperty(int) 。在关系数据库中,它们被映射到包含以 | 分隔的项目列表的文本字段中。例如,[1, 2, 3] 被映射到 |1|2|3| 。
对于字符串列表,项目被转义,项目中的任何 | 都被 || 替换。无论如何,这是一个内部表示,对用户是透明的。
例如,您可以按以下方式使用 list:string :
>>> db.define_table('product',
... Field('name'),
... Field('colors', 'list:string'))
<Table product (id, name, colors)>
>>> db.product.colors.requires = IS_IN_SET(('red', 'blue', 'green'))
>>> db.product.insert(name='Toy Car', colors=['red', 'green'])
1
>>> products = db(db.product.colors.contains('red')).select()
>>> for item in products:
... print(item.name, item.colors)
...
Toy Car ['red', 'green']
list:integer 的工作方式相同,但项目必须是整数。
与往常一样,这些要求是在表单层面执行的,而不是在数据库中调用 insert 时。
对于
list:<type>字段,contains(value)运算符映射到一个复制的查询中,该查询检查列表是否包含value元素。contains运算符也适用于常规的string字段和text字段,它映射到LIKE '%value%'。
list:reference 和 contains(value) 运算符对于反规范化多对多关系特别有用。以下是一个示例:
>>> db.define_table('tag',
... Field('name'),
... format='%(name)s')
<Table tag (id, name)>
>>> db.define_table('product',
... Field('name'),
... Field('tags', 'list:reference tag'))
<Table product (id, name, tags)>
>>> a = db.tag.insert(name='red')
>>> b = db.tag.insert(name='green')
>>> c = db.tag.insert(name='blue')
>>> db.product.insert(name='Toy Car', tags=[a, b, c])
1
>>> products = db(db.product.tags.contains(b)).select()
>>> for item in products:
... print(item.name, item.tags)
...
Toy Car [1, 2, 3]
>>> for item in products:
... print(item.name, db.product.tags.represent(item.tags))
...
Toy Car red, green, blue
请注意,list:reference tag 字段获取到默认约束
requires = IS_IN_DB(db, db.tag._id, db.tag._format, multiple=True)
它在表单中生成一个 SELECT/OPTION 多个项目的下拉框。
还要注意,此字段有一个默认的 represent 属性,它将引用列表表示为逗号分隔的格式化显示的引用列表。这用于只读的 forms 。
虽然
list:reference有一个默认验证器和一个默认表示,但list:integer和list:string没有。因此,如果要在表单中使用验证器,则需要给字段添加IS_IN_SET或IS_IN_DB验证器。
“表” 的继承
可以创建一个包含另一个表中所有字段的表。将另一个表代替字段传递给 define_table 就足够了。例如
>>> db.define_table('person', Field('name'), Field('gender'))
<Table person (id, name, gender)>
>>> db.define_table('doctor', db.person, Field('specialization'))
<Table doctor (id, name, gender, specialization)>
可以定义一个不存储在数据库中的虚拟表,以便在多个其他地方重用它。例如:
now = datetime.datetime.utcnow
signature = db.Table(db, 'signature',
Field('is_active', 'boolean', default=True),
Field('created_on', 'datetime', default=now),
Field('created_by', db.auth_user, default=auth.user_id),
Field('modified_on', 'datetime', update=now),
Field('modified_by', db.auth_user, update=auth.user_id))
db.define_table('payment', Field('amount', 'double'), signature)
此示例假设启用了标准的 py4web 身份验证。
请注意,如果您使用 Auth ,py4web 就已经为您创建了一个这样的表:
auth = Auth(db)
db.define_table('payment', Field('amount', 'double'), auth.signature)
使用表继承时,如果希望继承表继承验证器,请务必在定义继承表之前定义父表的验证器。
filter_in 和 filter_out
在将该字段的值插入数据库之前和从数据库检索字段的值之后,可以为每个要处理的字段定义一个过滤器。
例如,想象一下,你想在 JSON格 式的字段中存储一个可序列化的 Python 数据结构。以下是实现这一目标的方法:
>>> import json
>>> db.define_table('anyobj',
... Field('name'),
... Field('data', 'text'))
<Table anyobj (id, name, data)>
>>> db.anyobj.data.filter_in = lambda obj: json.dumps(obj)
>>> db.anyobj.data.filter_out = lambda txt: json.loads(txt)
>>> myobj = ['hello', 'world', 1, {2: 3}]
>>> aid = db.anyobj.insert(name='myobjname', data=myobj)
>>> row = db.anyobj[aid]
>>> row.data
['hello', 'world', 1, {'2': 3}]
另一种实现此目的的方法是使用 SQLCustomType 类型的字段,如 自定义的 Field 类型 中所述。
在记录被 insert、 delete 和 update 时的回调
PY4WEB 提供了一种机制,用于注册在 insert、 delete 和 update 记录之前和/或之后调用的回调函数。
每个表存储六个回调列表:
db.mytable._before_insert
db.mytable._after_insert
db.mytable._before_update
db.mytable._after_update
db.mytable._before_delete
db.mytable._after_delete
您可以通过将回调函数添加到相应的回调函数列表中来注册它。需要注意的是,根据功能的不同,回调函数需要具有不同的签名。
这最好用例子来解释:
>>> db.define_table('person', Field('name'))
<Table person (id, name)>
>>> def pprint(callback, *args):
... print("%s%s" % (callback, args))
...
>>> db.person._before_insert.append(lambda f: pprint('before_insert', f))
>>> db.person._after_insert.append(lambda f, i: pprint('after_insert', f, i))
>>> db.person.insert(name='John')
before_insert(<OpRow {'name': 'John'}>,)
after_insert(<OpRow {'name': 'John'}>, 1)
1
>>> db.person._before_update.append(lambda s, f: pprint('before_update', s, f))
>>> db.person._after_update.append(lambda s, f: pprint('after_update', s, f))
>>> db(db.person.id == 1).update(name='Tim')
before_update(<Set ("person"."id" = 1)>, <OpRow {'name': 'Tim'}>)
after_update(<Set ("person"."id" = 1)>, <OpRow {'name': 'Tim'}>)
1
>>> db.person._before_delete.append(lambda s: pprint('before_delete', s))
>>> db.person._after_delete.append(lambda s: pprint('after_delete', s))
>>> db(db.person.id == 1).delete()
before_delete(<Set ("person"."id" = 1)>,)
after_delete(<Set ("person"."id" = 1)>,)
1
如您所见:- f 传递 OpRow 对象,其中包含插入或更新的数据。 - i 传递新插入记录的 id。- s 传递用于更新或删除操作的 Set 对象。 OpRow 是一个专门用于存储(字段,值)对的辅助对象,您可以将其视为一个普通的字典,甚至可以使用属性表示法的语法来操作(即 f.name 和 f['name'] 是等效的)。
这些回调函数的返回值应该是 None 或者 False 。如果任意一个 _before_* 回调函数返回的值是 True ,对应的实际 insert/update/delete 操作将被终止。
有时,回调可能需要在相同或不同的表中执行更新,并且希望避免触发其他回调,这可能会导致无限循环。
为此, Set 对象有一个 update_naive 方法,其工作方式类似于update,但忽略其执行前后可能触发的其它回调。
数据库的级联操作
数据库模式可以定义触发删除相关记录的关系,称为级联。当记录因级联而被删除时,DAL 不会收到通知。因此,级联导致的删除不会触发 *_delete 回调。
记录版本控制
当记录被单独修改时,可以要求 py4web 保存记录的每个副本。有不同的方法可以做到这一点,并且可以使用以下语法一次对所有表完成设置:
auth.enable_record_versioning(db)
这种设置需要 Auth ,也可以像下面一样对每个单独的表进行设置。
假设有下面的表:
db.define_table('stored_item',
Field('name'),
Field('quantity', 'integer'),
Field('is_active', 'boolean',
writable=False, readable=False, default=True))
请注意,名为 is_active 的隐藏布尔字段,其默认值为 True
我们可以让 py4web 创建一个新表(在相同或不同的数据库中),并在修改时将每条记录的所有先前版本存储在表中。
使用下面的方法实现:
db.stored_item._enable_record_versioning()
或使用更多参数:
db.stored_item._enable_record_versioning(archive_db=db,
archive_name='stored_item_archive',
current_record='current_record',
is_active='is_active')
archive_db=db 命令告诉 py4web 将归档表存储在与 stored_item 表相同的数据库中。archive_name 设置存档表的名称。存档表具有与原始表 stored_item 相同的字段,除了唯一字段不再是唯一的(因为它需要存储多个版本),并且有一个额外的字段,它是对 stored_item 表中当前记录的引用,其名称由 current_record 指定。
当记录被删除时,它们并没有真正被删除。已删除的记录会被复制到 stored_item_archive 表中(就像它被修改时一样),并且 is_active 字段被设置为 False。通过启用记录版本控制,py4web 在此表上设置了一个 common_filter ,该筛选器隐藏了表 stored_item 中 is_active 字段设置为 False 的所有记录。 _enable_record_versioning 方法中的 is_active 参数允许指定 common_filter 用于确定字段是否被删除的字段的名称。
通用的过滤器(Common filters)
通用过滤器(Common filter)是上述多用户概念的推广。它提供了一种简单的方法来防止重复相同的查询。例如,考虑下表:
db.define_table('blog_post',
Field('subject'),
Field('post_text', 'text'),
Field('is_public', 'boolean'),
common_filter = lambda query: db.blog_post.is_public == True)
此表中的任何查询、删除或更新都将仅包括 “公开” 的博客帖子。该属性也可以在运行时修改:
db.blog_post._common_filter = lambda query: ...
它既是一种避免在每次博客文章搜索中重复 “db.blog_post.is_public==True” 短语的方法,也是一种安全增强,可以防止您忘记设置 “禁止查看” 非公开文章。
如果您确实希望查询过滤器遗漏的项目(例如,允许管理员查看非公开帖子),您可以删除过滤器:
db.blog_post._common_filter = None
或者忽略过滤器:
db(query, ignore_common_filters=True)
请注意,appadmin 接口会自动忽略 common_filters。
自定义的 Field 类型
在不使用 filter_in 和 filter_out 的时候,还可以定义新的自定义字段类型。例如,下面假设你要定义一个存储 IP 地址数据的自定义类型:
>>> def ip2int(sv):
... "Convert an IPV4 to an integer."
... sp = sv.split('.'); assert len(sp) == 4 # IPV4 only
... iip = 0
... for i in map(int, sp): iip = (iip<<8) + i
... return iip
...
>>> def int2ip(iv):
... "Convert an integer to an IPV4."
... assert iv > 0
... iv = (iv,); ov = []
... for i in range(3):
... iv = divmod(iv[0], 256)
... ov.insert(0, iv[1])
... ov.insert(0, iv[0])
... return '.'.join(map(str, ov))
...
>>> from pydal import SQLCustomType
>>> ipv4 = SQLCustomType(type='string', native='integer',
... encoder=lambda x : str(ip2int(x)), decoder=int2ip)
>>> db.define_table('website',
... Field('name'),
... Field('ipaddr', type=ipv4))
<Table website (id, name, ipaddr)>
>>> db.website.insert(name='wikipedia', ipaddr='91.198.174.192')
1
>>> db.website.insert(name='google', ipaddr='172.217.11.174')
2
>>> db.website.insert(name='youtube', ipaddr='74.125.65.91')
3
>>> db.website.insert(name='github', ipaddr='207.97.227.239')
4
>>> rows = db(db.website.ipaddr > '100.0.0.0').select(orderby=~db.website.ipaddr)
>>> for row in rows:
... print(row.name, row.ipaddr)
...
github 207.97.227.239
google 172.217.11.174
SQLCustomType 是一个字段类型工厂。参数 type 必须是标准的 py4 web 类型之一,它告诉 py4web 将输入的字段的值在 py4web 程序中按哪种类型对待;参数 native 是数据库中存储数据的字段类型,允许的名称取决于数据库引擎;参数 encoder 是存储数据时应用的可选变换函数;参数 decoder 是可选的逆变换函数。
此功能被标记为实验性的,因为它会使您的代码无法在数据库引擎之间移植。
它不适用于 Google App Engine NoSQL。
使用不定义表的 DAL
DAL 可以从任何 Python 程序中使用,只需执行以下操作:
from pydal import DAL, Field
db = DAL('sqlite://storage.sqlite', folder='path/to/app/databases')
即,导入 DAL,连接并指定包含 .table 文件的文件夹(app/databases 文件夹)。
为了访问数据及其属性,我们仍然需要定义我们将使用 db.define_table 访问的所有表。
如果我们只需要访问数据,而不需要访问 py4web 表属性,那么不需要再重新定义表,只需要让 py4web 从 .table 文件中的元数据中读取必要的信息:
from py4web import DAL, Field
db = DAL('sqlite://storage.sqlite', folder='path/to/app/databases', auto_import=True)
这允许我们访问任意的 db.table ,而无需再重新定义要访问的表。
分布式事务
在撰写本文时,只有 PostgreSQL、MySQL 和 Firebird 支持此功能,因为它们公开了API 用于两阶段的提交。
假设你有两个(或更多)连接到不同的 PostgreSQL 数据库,例如:
db_a = DAL('postgres://...')
db_b = DAL('postgres://...')
在您的模型或控制器中,您可以同时提交它们:
DAL.distributed_transaction_commit(db_a, db_b)
如果失败,此函数将回滚并引发 Exception。
在控制器中,当一个 action 返回时,如果您有两个不同的数据库连接并且没有调用上述函数,py4web 会分别提交它们。这意味着有可能一个提交成功,另一个提交失败。分布式事务可以防止这种情况发生。
将数据从一个数据库复制到另一个数据库
假设您一直在使用以下数据库的情况:
db = DAL('sqlite://storage.sqlite')
并且您希望使用不同的连接字符串切换到另一个数据库:
db = DAL('postgres://username:password@localhost/mydb')
在切换之前,您需要移动数据并为新数据库重建所有元数据。我们假设新数据库存在,但也假设它是空的。
陷阱
关于新 DAL 和适配器的说明
数据库抽象层的源代码在 2010 年被完全重写。虽然它保持向后兼容,但重写使其更加模块化,更容易扩展。这里我们解释一下主要逻辑。
模块 “dal.py” 主要定义了以下类:
ConnectionPool
BaseAdapter extends ConnectionPool
Row
DAL
Reference
Table
Expression
Field
Query
Set
Rows
除了 BaseAdapter 之外,在前面的章节中已经解释了它们的用法。当 Table 或 Set 对象的方法需要与数据库通信时,它们将生成 SQL 和/或函数调用的任务委托给适配器的方法。
例如:
db.mytable.insert(myfield='myvalue')
调用
Table.insert(myfield='myvalue')
该命令通过返回以下内容来委派适配器:
db._adapter.insert(db.mytable, db.mytable._listify(dict(myfield='myvalue')))
这里 db.mytable._listify 将参数的 dict 转换为 (field,value) 列表,并调用 adapter 的 insert 方法。 db._adapter 执行以下类似的操作:
query = db._adapter._insert(db.mytable, list_of_fields)
db._adapter.execute(query)
其中第一行构建查询,第二行执行查询。
BaseAdapter 定义了适配器的所有接口。
在撰写本书时,pyDAL 包含以下适配器:
SQLiteAdapter extends BaseAdapter
JDBCSQLiteAdapter extends SQLiteAdapter
MySQLAdapter extends BaseAdapter
PostgreSQLAdapter extends BaseAdapter
JDBCPostgreSQLAdapter extends PostgreSQLAdapter
OracleAdapter extends BaseAdapter
MSSQLAdapter extends BaseAdapter
MSSQL2Adapter extends MSSQLAdapter
MSSQL3Adapter extends MSSQLAdapter
MSSQL4Adapter extends MSSQLAdapter
FireBirdAdapter extends BaseAdapter
FireBirdEmbeddedAdapter extends FireBirdAdapter
InformixAdapter extends BaseAdapter
DB2Adapter extends BaseAdapter
IngresAdapter extends BaseAdapter
IngresUnicodeAdapter extends IngresAdapter
GoogleSQLAdapter extends MySQLAdapter
NoSQLAdapter extends BaseAdapter
GoogleDatastoreAdapter extends NoSQLAdapter
CubridAdapter extends MySQLAdapter (experimental)
TeradataAdapter extends DB2Adapter (experimental)
SAPDBAdapter extends BaseAdapter (experimental)
CouchDBAdapter extends NoSQLAdapter (experimental)
IMAPAdapter extends NoSQLAdapter (experimental)
MongoDBAdapter extends NoSQLAdapter (experimental)
VerticaAdapter extends MSSQLAdapter (experimental)
SybaseAdapter extends MSSQLAdapter (experimental)
它们重写了 BaseAdapter 的行为。
每个适配器都有这种类似的结构:
class MySQLAdapter(BaseAdapter):
# specify a driver to use
driver = globals().get('pymysql', None)
# map py4web types into database types
types = {
'boolean': 'CHAR(1)',
'string': 'VARCHAR(%(length)s)',
'text': 'LONGTEXT',
...
}
# connect to the database using driver
def __init__(self, db, uri, pool_size=0, folder=None, db_codec ='UTF-8',
credential_decoder=lambda x:x, driver_args={},
adapter_args={}):
# parse uri string and store parameters in driver_args
...
# define a connection function
def connect(driver_args=driver_args):
return self.driver.connect(**driver_args)
# place it in the pool
self.pool_connection(connect)
# set optional parameters (after connection)
self.execute('SET FOREIGN_KEY_CHECKS=1;')
self.execute("SET sql_mode='NO_BACKSLASH_ESCAPES';")
# override BaseAdapter methods as needed
def lastrowid(self, table):
self.execute('select last_insert_id();')
return int(self.cursor.fetchone()[0])
以各种适配器为例,应该很容易编写新的适配器。
当创建 db 实例时:
db = DAL('mysql://...')
DAL() 中 uri 字符串的前缀定义了适配器。在以下字典中定义的映射,在 “dal.py” 中也有定义:
couchdb |
pydal.adapters.couchdb.CouchDB |
cubrid |
pydal.adapters.mysql.Cubrid |
db2:ibm_db_dbi |
pydal.adapters.db2.DB2IBM |
db2:pyodbc |
pydal.adapters.db2.DB2Pyodbc |
firebird |
pydal.adapters.firebird.FireBird |
firebird_embedded |
pydal.adapters.firebird.FireBirdEmbedded |
google:MySQLdb |
pydal.adapters.google.GoogleMySQL |
google:datastore |
pydal.adapters.google.GoogleDatastore |
google:datastore+ndb |
pydal.adapters.google.GoogleDatastore |
google:psycopg2 |
pydal.adapters.google.GooglePostgres |
google:sql |
pydal.adapters.google.GoogleSQL |
informix |
pydal.adapters.informix.Informix |
informix-se |
pydal.adapters.informix.InformixSE |
ingres |
pydal.adapters.ingres.Ingres |
ingresu |
pydal.adapters.ingres.IngresUnicode |
pydal.adapters.postgres.JDBCPostgre |
|
pydal.adapters.sqlite.JDBCSQLite |
|
pydal.adapters.sqlite.JDBCSQLite |
|
mongodb |
pydal.adapters.mongo.Mongo |
mssql |
pydal.adapters.mssql.MSSQL1 |
mssql2 |
pydal.adapters.mssql.MSSQL1N |
mssql3 |
pydal.adapters.mssql.MSSQL3 |
mssql3n |
pydal.adapters.mssql.MSSQL3N |
mssql4 |
pydal.adapters.mssql.MSSQL4 |
mssql4n |
pydal.adapters.mssql.MSSQL4N |
mssqln |
pydal.adapters.mssql.MSSQL1N |
mysql |
pydal.adapters.mysql.MySQL |
oracle |
pydal.adapters.oracle.Oracle |
postgres |
pydal.adapters.postgres.Postgre |
postgres2 |
pydal.adapters.postgres.PostgreNew |
postgres2:psycopg2 |
pydal.adapters.postgres.PostgrePsycoNew |
postgres3 |
pydal.adapters.postgres.PostgreBoolean |
postgres3:psycopg2 |
pydal.adapters.postgres.PostgrePsycoBoolean |
postgres:psycopg2 |
pydal.adapters.postgres.PostgrePsyco |
pytds |
pydal.adapters.mssql.PyTDS |
sapdb |
pydal.adapters.sap.SAPDB |
spatialite |
pydal.adapters.sqlite.Spatialite |
spatialite:memory |
pydal.adapters.sqlite.Spatialite |
sqlite |
pydal.adapters.sqlite.SQLite |
sqlite:memory |
pydal.adapters.sqlite.SQLite |
sybase |
pydal.adapters.mssql.Sybase |
teradata |
pydal.adapters.teradata.Teradata |
vertica |
pydal.adapters.mssql.Vertica |
然后,适配器本身会更详细地解析uri字符串。适配器的更新列表可以通过字典获得。
对于任何适配器,您都可以在全局范围内用不同的驱动程序替换已有的驱动程序(不是线程安全的):
import MySQLdb as mysqldb
from pydal.adapters.mysql import SQLAdapter
SQLAdapter.driver = mysqldb
即 mysqldb 必须是具有 .connect() 方法的模块。您可以指定可选的驱动程序参数和适配器参数:
db = DAL(..., driver_args={}, adapter_args={})
对于已识别的适配器,您还可以在 adapter_args 中简单地指定名称:
from pydal.adapters.mysql import MySQL
assert "mysqldv" in MySQL.drivers
db = DAL(..., driver_args={}, adapter_args={"driver": "mysqldb"})
SQLite
SQLite 不支持删除和更改列。这意味着 py4web 迁移在一定程度上是可行的。如果从表中删除字段,该列将保留在数据库中,但对 py4web 不可见。如果您决定恢复该列,py4web 将尝试重新创建它,但会失败。在这种情况下,您必须添加设置 fake_migrate=True ,以便在不尝试再次添加列的情况下重建元数据。同样,出于同样的原因,SQLite 不知道列的类型的任何变化。如果在字符串字段中插入一个数字,它将存储为字符串。如果稍后模型的类型 “string” 更改为类型 “integer” ,SQLite 将继续将数字保持为字符串不变,这可能会在您尝试提取数据时导致问题。
SQLite 没有布尔类型。py4web 内部将布尔值映射为 1 个字符串,其中 'T' 和 'F' 分别表示 True 和 False。DAL 完全处理了这一点;真正布尔值的抽象效果很好。但是,如果您直接使用 SQL 更新 SQLite 表,请注意 py4web 实现,并避免使用 0 和 1 值。
MySQL
MySQL 不支持在单个事务中使用多个 ALTER TABLE。这意味着任何迁移过程都被分解为多个提交。如果发生了导致失败的事情,则可能会中断迁移(py4web 元数据不再与数据库中的实际表结构同步)。这很不幸,但可以防止(一次迁移一个表),也可以在之后修复(将 py4web 模型还原为数据库中与表结构相对应的模型,设置 fake_migrate=True ,在重建元数据后,设置fake fake_migrate=False 并再次迁移表)。
Google SQL
Google SQL 与 MySQL 存在相同的问题,甚至更多。特别是,表元数据本身必须存储在数据库中一个不会被 py4web 迁移的表中。这是因为 Google App Engine 具有只读文件系统。Google SQL 中的 PY4WEB 迁移与上述 MySQL 问题相结合可能会导致元数据损坏。同样,可以防止这种情况(通过一次性迁移表,然后设置 migrate=False,使元数据表不再被访问),也可以在之后修复(通过使用 Google dashboard 访问数据库,并从名为 py4web_filesystem 的表中删除任何损坏的条目)。
MSSQL (Microsoft SQL Server)
低于 MSSQL 2012 的版本不支持 SQL OFFSET 关键字。因此,数据库无法进行分页。当执行 limitby=(a, b) 时,py4web 将获取前 a+b 行并丢弃前 a 行。与其他数据库引擎相比,这可能会导致相当大的开销。如果您使用 MSSQL 2005 及以上版本,建议使用的前缀是``mssql3://`` ,它提供了一种避免获取整个非分页结果集的方法。如果使用的是 MSSQL 2012 及以上版本,请使用 mssql4://,它采用 OFFSET ... ROWS ... FETCH NEXT ... ROWS ONLY 结构,以原生方式支持分页,不会像其他后端那样产生性能损耗。 mssql:// 还强制(出于历史原因)使用 text 列,在最近的版本(从 2005 年开始)中,文本列被 varchar(max) 取代。如果你不想面对正式弃用的 text 列的一些限制,应该使用 mssql3:// 和 mssql4:// 。
MSSQL 在使用具有 ONDELITE CASCADE 的表时会有循环引用的问题。这是 MSSQL 一个的漏洞,您可以通过将所有引用字段的 ondelete 属性设置为 “NO ACTION” 来避免问题出现。您也可以在定义表之前一次性完成此操作:
db = DAL('mssql://....')
for key in db._adapter.types:
if ' ON DELETE %(on_delete_action)s' in db._adapter.types[key]:
db._adapter.types[key] = db._adapter.types[key].replace('%(on_delete_action)s', 'NO ACTION')
MSSQL 在传递给 DISTINCT 关键字的参数方面也存在问题,因此,下面的可以
db(query).select(distinct=True)
这就不行
db(query).select(distinct=db.mytable.myfield)
Oracle
Oracle 也不支持分页。它既不支持 OFFSET 也不支持 LIMIT关 键字。PY4WEB 通过将 db(...).select(limitby=(a, b)) 转换为复杂的三层嵌套的 select(如 Oracle 官方文档所建议)来实现分页。这适用于简单的查询,但对于涉及别名字段和/或连接的复杂的查询可能会中断。
Google NoSQL (Datastore)
Google NoSQL (Datastore) 不允许连接、左连接、聚合、表达式或涉及多个表的 OR,“like” 运算符在 “text” 字段中搜索。
事务受到限制,py4web 不会自动提供(您需要使用 Google API run_in_transaction ,您可以在 Google App Engine 的在线文档中查找)。
谷歌还限制了您在每个查询中可以检索的记录数量(在撰写本文时为 1000 条)。在 Google 数据存储中,记录 ID 是整数,但它们不是连续的。在 SQL 中, “list:string” 类型被映射为 “text” 类型,而 在Google Datastore 中,它被映射为 ListStringProperty。类似地,“list:integer” 和 “list:reference” 被映射到 ListProperty 中。这使得在 Google NoSQL 上搜索这些字段类型中的内容比在 SQL 数据库上更高效。